
Author: Amitai B. Erfanian, Ryan Scopio
Abstract
This research project compares the two most commonly used machine learning algorithms which help the technology imitate the human learning process through computational formulas. The two learning algorithms explored are the Genetics and Backpropagation learning algorithms. Each learning algorithm was evaluated through three tests (XOR, Reptile Classification, and Sin(x) prediction) each focusing on a different component of the learning algorithm regarding its overall efficiency. The efficiency of a learning algorithm was determined by both the speed of training a learning algorithm along with the algorithm’s overall prediction accuracy for each test. The goal of this research project is to define the strengths and weaknesses of each algorithm to further progress the development of artificial intelligence throughout the world.
Introduction
The purpose of this research project is to compare the overall efficiency of two bb algorithms, which are defined in the glossary provided within Appendix A. In this research project, the overall efficiency of each learning algorithm was specifically tested under supervised data (see Appendix A). The two learning algorithms, Genetics and Backpropagation, are used by the majority of professionals in the field of Artificial Intelligence/Machine Learning. The overarching goal of this research paper is to provide new information to those using Machine learning algorithms in globally beneficial applications such as recognizing handwriting how driving cars.
Lit Review
In the field of machine learning, large data sets are used to find patterns within the question that the machine is meant to solve (Mitchell, 2018). However, without a strong structure for the data, the machine is unable to identify any pattern, and thus, cannot formulate a solution to the problem. For this reason, computer scientists have created data structures (see Appendix A) in computer science such as Neural Networks to organize the data in a format optimal for machine learning.

A Neural Network, as defined by various sources such as Grimson (2017), Loy (2018), Sethbling (2015), Sanderson (2017), and Tyka (2015), is a computer data structure that acts as a mathematical function, mapping specific inputs to corresponding outputs (Grimson, 2017; Loy, 2018; SethBling, 2015; Sanderson, “But what is a Neural Network? Deep learning, chapter 1” 2017; Tyka 2015). The Neural Network is split into layers which each contain small data structures called neurons (Loy, 2018; SethBling, 2015; Sanderson, “But what is a Neural Network? Deep learning, chapter 1” 2017). As stated by Amini from the Massachusetts Institute of Technology (2018), Glorot and Bengio of Google Deepmind (2018), and Larochelle (2016), when a Neural Network feeds-forward (see Appendix A) or computes its overall output, each neuron calculates its value before passing it on to all the neurons in the layer to come (Amini, 2018; Glorot & Bengio, 2018; Larochelle, 2016; Loy, 2018). The connections between neurons in separate layers, in the field of computer science, are referred to as dendrites (Raval, “Intro to deep learning #1” 2017; Raval, “Intro to deep learning #2” 2017). Each dendrite within a Neural Network has a weight value attached to it which represents the strength of the neuron-to-neuron connection (Raval, “Intro to deep learning #2” 2017; SethBling, 2015). When a neuron passes its value onto the neuron in the upcoming layer, the neuron multiplies its value with the weight of the corresponding dendrite (Loy, 2018; McCaffrey, 2014). However, this process causes the values within the neurons of the Neural Network to become too large and eventually meaningless. For this reason, many Machine Learning experts, such as Mansor and Sathasivam (2016), use activation functions (see Appendix A) to constrain the output of each neuron into a range manageable for each neuron (Mansor & Sathasivam, 2016). The value of each neuron is best modeled by the following equation where ‘x’ is the input vector, ‘w’ weight vector that is attached to the dendrite, ‘n’ is the total number of neurons in the previous layer, and ‘a’ is the activation function used within the Neural Network layer (Sanderson, “But what is a Neural Network? Deep learning, chapter 1” 2017; Rosenblatt, 1962).
Upon creation, McCaffrey (2014) states that each neuron’s dendrite weight is randomly assigned using a normal curve, giving the Neural Network a normal distribution of random weights before it starts training (McCaffrey, 2014). According to Raval (2017), a researcher at Columbia University, in order for a Neural Network to undergo the learning process (see Appendix A), it must be paired with a learning algorithm (Raval, “Intro to deep learning #1” 2017; Sethbling, 2015). Each learning algorithm has a completely different method of training a Neural Network which contributes to their differing results. The two learning algorithms analyzed in this research project are Genetics and Backpropagation.
According to Mallawaarachchi (2017) and Winston (2010), the Genetics Learning Algorithm begins the training process by creating a population of Neural Networks (Mallawaarachchi, 2017; Winston, 2010). From this population, the Genetics Learning Algorithm runs a fitness calculation (see Appendix A) on each Neural Network within the population (Mallawaarachchi, 2017). After running the calculation, the algorithm then ranks the Neural Networks based on their fitness rating (see Appendix A) from greatest to least (Mallawaarachchi, 2017). After ranking the Neural Networks, the Genetics Learning Algorithm then splits the population into three groups: secure, mutate, and destroy (Goldberg, 1989). The Neural Networks within the secure category, usually inclusive of the top ten percent of the population, are left untouched and move on to the next generation (see Appendix A) of the learning process (Goldberg, 1989). The middle 80 percent of Neural Networks within the population are placed into the mutation category (Goldberg, 1989). The Genetics Learning Algorithm then evolves Neural Networks in the mutation category by slightly shifting their dendrite weight values to mimic those of the secure category (Goldberg, 1989). Finally, the Neural Networks within the destroy category, composed of the bottom ten percent of the population, are destroyed and recreated, allowing new randomized Neural Networks to enter the artificial gene pool (Goldberg, 1989). Once all three categories and their corresponding functions are carried out, the Genetics Learning Algorithm returns the Neural Network with the highest fitness rating also known as the Neural Network of best fit (Goldberg, 1989). Once the best fit Neural Network is selected, the learning process for the Genetics Learning Algorithm is complete (Mallawaarachchi, 2017).
Contrary to the Genetics Learning Algorithm’s population of neural networks, the Backpropagation Learning Algorithm starts the learning process with a single Neural Network (Raval, “Backpropagation explained” 2018; Sanderson, “Gradient descent, how Neural Networks learn: Deep learning, chapter 2” 2017). The Backpropagation Learning Algorithm then calculates the error (see Appendix A) of the Neural Network on a single test composed of one input and its corresponding outputs (Reed & Marks, 1999; Sanderson, “What is backpropagation really doing? Deep learning, chapter 3” 2017). At this point, the Backpropagation Learning Algorithm finds each dendrite’s weight update (see Appendix A) or the direction and distance which the learning algorithm adjusts each dendrite to minimize the Neural Network’s error (McCaffrey, 2014; Sanderson, “What is backpropagation really doing? Deep learning, chapter 3” 2017; Sanderson, “Backpropagation calculus: Deep learning, chapter 4” 2017). The equation for any given dendrite’s weight update is modeled by the following equation where ‘e’ is the partial derivative of the error function with respect to the attached neuron of the Neural Network for the specific row of test data, ‘i’ is the input to the neuron, ‘l’ is the learning rate (see Appendix A) set by the programmer, and ‘a’ is the activation function used within the Neural Network layer (Sanderson, “Backpropagation calculus: Deep learning, chapter 4” 2017; Reed & Marks, 1999).

Following this calculation, the Backpropagation Learning Algorithm adds the dendrite weight to the corresponding weight update, essentially training the Neural Network (Raval, “Backpropagation explained” 2018; Sanderson, “What is backpropagation really doing?” 2017). The Backpropagation Learning Algorithm will continue to repeat the weight update process, lowering the Neural Network’s error with each Epoch (see Appendix A) and resulting in a Neural Network with the desired error.
More advanced versions of the Backpropagation Learning Algorithm include concepts such as momentum (Reed & Marks, 1999). Momentum is the sum of the prior weight updates for a specific dendrite multiplied by the momentum rate (see Appendix A) and added onto the new dendrite weight update (Reed & Marks, 1999). This concept allows the Backpropagation to decrease the training time by skipping over large periods of idle training time known as plateaus (see Appendix A).
Research Gap
While a large amount of research has been performed on each learning algorithm individually, the Genetics Learning Algorithm has yet to be thoroughly compared with the Backpropagation Learning Algorithm. This gap in the research is exactly what this research project aims to fill by comparing the overall efficiency of two learning algorithms.
Research Question
The purpose of this research project is to answer the question: Which learning algorithm is the most efficient when training on supervised data? In this research project, the efficiency of a learning algorithm will be determined by both the speed at which the learning algorithm trains a Neural Network and the overall accuracy of the Neural Network at the given task.
Hypothesis
The expected outcome of this research project is that the Genetics Learning Algorithm will outperform the Backpropagation Learning Algorithm in situations where the problem is less abstract/complex. This hypothesis was derived from previous observations on the two algorithms as well as other research papers on the algorithms themselves. Additionally, it has been commonly known in the Machine Learning field that the Genetics Learning Algorithm has problems with overfitting (see Appendix A) which may affect the accuracy of the neural network.
Methodology
The methodology of grounded theory, as defined by Anselm Strauss and Juliet Corbin, (1994) is “a general methodology for developing theory that is grounded in data systematically gathered and analyzed” (Strauss & Corbin, 1994). This research project follows the same system by gathering data on how efficiently a Neural Network can complete a specific task such as differentiating reptiles from other animals. The data gathered from such tasks also include the number of epochs (See Appendix A), the total training time for each learning algorithm, the total error or percent chance of failure the Neural Network has when making predictions regarding new data, and the amount of test data given to each Neural Network to train from. This data is then analyzed comparatively to find the differences between the two learning algorithms – the Genetics Learning Algorithms and Backpropagation Learning Algorithm.
Research Stages
This research project was split into three main tests, each focusing on a different aspect of the learning algorithms’ overall efficiency: training speed when given a simple task, training speed when given a complex task, and prediction accuracy. In this research project specifically, the tests were all created using supervised or labeled data. In addition, the values of learning rate and momentum were individually found for each of the main tests within the research through preliminary tests on the Backpropagation Learning Algorithm. These values were adjusted through a process of trial and error most of which started with a value derived from previous research.
The first test, XOR Test, was designed to address the learning speed of each algorithm when dealing with a simple task. The second test, Reptile Classification Test, was designed to evaluate the efficiency of each learning algorithm when dealing with data that follows a more complex pattern than XOR Test data. Finally, the third test, Sin Graph Test, was designed to evaluate each learning algorithm’s speed when predicting values that follow a complex mathematical pattern.
XOR Test
The purpose of this test was to find the training time of the two algorithms when dealing with a simple task. The task that each Neural Network was trained for in this specific test is the XOR gate. An XOR gate is a computer logic gate (see Appendix A) that receives two or more inputs and results in one output. In this specific application, the XOR gate used has two inputs and one output. The inputs to the XOR gate are binary, meaning they are true or false, one or zero. The result of an XOR gate is true if one, and only one of the gate’s inputs, is true.
The Neural Networks created for each learning algorithm were designed with two neurons in the first layer, two neurons in the second layer, and one neuron in the output layer. The activation function chosen for this specific task was the sigmoid activation function (see Appendix D) because of its output range of exactly zero to one. The sigmoid activation function was found within the research paper by Prajit Ramachandran, Barret Zoph, and Quoc V. Le (2017) of the Google Brain project and the list of activation functions by Shah (2017) (Ramachandran, Zoph, & Le, 2017; Shah, 2017; Raval, “Which activation function should I use?” 2017). The parameters for each learning algorithm were also calculated for this specific task. For example, the population for the Genetics Learning Algorithm was set to 500 Neural Networks while the Backpropagation Learning Algorithm had its learning rate and momentum rate each set to 0.2 and 0.0125 respectively.
Similar to the structure and parameters of the Neural Networks and their corresponding learning algorithm, the dendrite weights at the beginning of the training process were also the same across all Neural Networks. The Neural Networks were trained on all possible values for an XOR gate with two inputs. Those values include (1, 0), (1, 1), (0, 1), and (0, 0), each of which was assigned a respective output of one, zero, one, and zero.
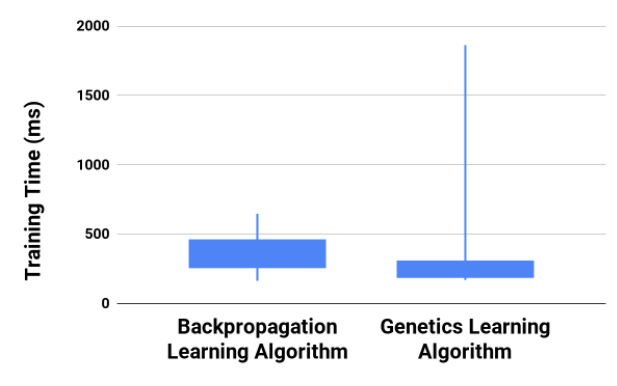
As shown in Figure 2, the Interquartile Range (IQR) or middle 50 percent of the Genetics Learning Algorithm was lower than that of the Backpropagation Learning Algorithm. This translated to a lower median training time between the two algorithms at about 30.617 milliseconds, in favor of the Genetics Learning Algorithm. However, the Backpropagation Learning Algorithm was found to be far more consistent. Based on the 30 tests run on the two learning algorithms, the Genetics Learning Algorithm had a maximum training time of 1863.1769 milliseconds and minimum training time of 169.9704 milliseconds while the Backpropagation Learning Algorithm’s training time spanned from a minimum of 163.9362 milliseconds to a maximum of 647.6394 milliseconds, giving the Genetics Learning Algorithm a much larger range than that of the Backpropagation Learning Algorithm. At first, these outlying values were seen as negligible outcasts within the data set, but as testing progressed, an increasing number of extreme values came into play (see Appendix B for the full set of test data).
This large range of training time is a result of the Genetics Learning Algorithm’s sporadic descent toward the lowest possible error, resulting in dramatically different training times. The cause for this sporadic descent is rooted within the algorithm’s mutation of the Neural Network population. These mutations or weight adjustments cause large changes within the Neural Network’s dendrites, resulting in a drastic change in error. The fluctuations in error would either yield beneficial or detrimental as seen in the data observed from the 30 XOR tests.
On the contrary, the Backpropagation Learning Algorithm was very concise in its descent, calculating its weight updates and scaling them with the specified learning rate. This use of a learning rate allowed the Backpropagation Learning Algorithm to limit its dendrite weight updates, lowering the magnitude of its weight adjustments towards a lower network error.
Reptile Classification Test
The purpose of this test was to find the training time of the two algorithms when dealing with a task more complex than that of the previous test. The task that each Neural Network was trained for was the classification of reptiles against all other animals. A reptile, as defined by Merriam-Webster Dictionary, is any cold-blooded, air-breathing animal (“Merriam Webster”).
Each animal that the Neural Networks trained on were defined by five main characteristics: number of legs, whether or not the animal has scales, whether or not the animal is cold-blooded, whether or not the animal breathes air, and whether or not the animal has fins. These characteristics were chosen specifically to allow the Neural Network to identify patterns and disregard the uncorrelated information with the ultimate result reptile classification. For example, the characteristic of whether or not an animal is cold-blooded is directly correlated with whether the animal is a reptile. On the other hand, the number of legs an animal has is not related at all to the classification of the animal as a reptile. This forces the Neural Network to independently decipher between the information to find what does and does not influence the classification of the animal.
Each characteristic was given to each of the two Neural Networks in the form of numerical values. The values representing the absence or presence of a characteristic within the animal were one for present and zero for absent. For example, the value given to the Neural Networks for an animal with scales would be one in comparison to an animal without scales which would have a value of zero. The output of the Neural Network was one if the animal inputted was a reptile and zero if the animal inputted was not a reptile.
The Neural Networks created for each learning algorithm were modeled off the input(s) and output(s) of the task. The Neural Networks were created with two layers. In the first layer, five neurons were created corresponding with one of the five characteristics defining each animal and one neuron in the output layer corresponding with the expected result. The activation function for this specific test was chosen as the sigmoid activation function (see Appendix D) because of its output range of exactly zero to one corresponding with the desired output of the Neural Networks given this task.
Similar to the structure of each Neural Network, the dendrite weights at the beginning of the training process were the same for each of the two Neural Networks. The parameters for each learning algorithm were meticulously chosen for this specific task. The Genetics Learning Algorithm, for example, was chosen to have a population size of 250 Neural Networks. On the other hand, the learning rate and momentum rate values of the Backpropagation Learning Algorithm were set to 0.035 and 0.0125 respectively.
The training data (see Appendix A) used by each of the learning algorithms was limited to five animals. The accuracy of each Neural Network was tested on data that neither learning algorithm was trained on. The accuracy of the Neural Networks corresponding for each of the two learning algorithms was recorded at different increments of training time. To ensure the accuracy of each test, the training time and training data were the same for each learning algorithm.
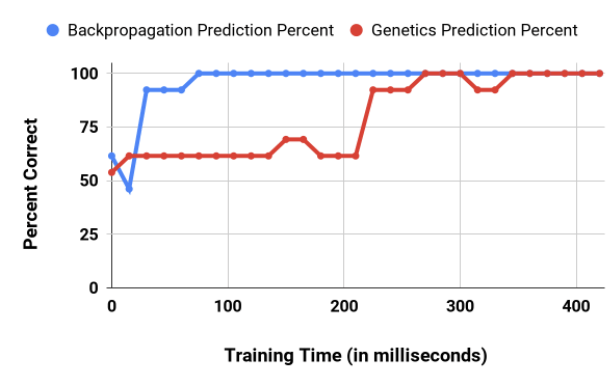
As shown in Figure 3, the Backpropagation Learning Algorithm greatly outperformed the Genetics Learning Algorithm. The Backpropagation Learning Algorithm was able to correctly identify all the animals in the data set with only 75 milliseconds of training time while the Genetics Learning Algorithm took 270 milliseconds to achieve the same accuracy level. This difference brings the training efficiency Backpropagation Learning Algorithm to approximately three times greater than that of the Genetics Learning Algorithm.
Unlike the Backpropagation Learning Algorithm, the Genetics Learning Algorithm was inconsistent in its prediction of reptiles. At 150 milliseconds, the Genetics Learning Algorithm achieved a short-lived accuracy of 69.23 percent which dropped back to 61.54 percent after training for an additional 30 milliseconds (all Reptile Classification Test results can be found in Appendix C). Similar to the scenario at 150 milliseconds, the Genetics Learning Algorithm also dropped from a 100 percent classification accuracy at 270 milliseconds to a 92.31 percent accuracy after 45 milliseconds of additional training. This drop inaccuracy was due to a process known in machine learning as overfitting (see Appendix A). According to Dietterich, the process of overfitting occurs when a learning algorithm starts to conform to the values it trains on rather than identifying the underlying pattern within the data set (Dietterich, 1995). As seen in Figure 3, the increase in training time caused the Genetics Learning Algorithm to occasionally overfit to the data it was training on, hindering its ability to predict new data accurately.
In addition to the overfitting experienced by the Genetics Learning Algorithm, Figure 3 also expresses the sporadic changes in error that occurs when the Genetics Learning Algorithm mutates the middle 80 percent of the population of Neural Networks. As seen in the interval between 150 and 315 milliseconds, the prediction accuracy of the Genetics Learning Algorithm increased drastically despite a few small decreases in overall accuracy. This data further backed the results found from the XOR test about the sporadic changes in the error of the Genetics Learning Algorithm.
Sine Graph Test
The purpose of this test was to evaluate the accuracy of each learning algorithm when predicting values that follow a complex mathematical pattern. The mathematical pattern chosen for this test was a sine wave due to its periodic nature, or predictable pattern. The Neural Networks assigned to each of the two learning algorithms were given 256 points that spanned over two periods of a sine curve used as training data. The number of points the Neural Networks were trained on was selected after several tests proved that the computer used for research could not handle training on a larger set of data. With those 256 points, both learning algorithms were trained until one reached an error of less than one percent. Following this, each learning algorithm was tasked with predicting the values of sine in the next two periods.
The Neural Networks were structured with five neurons in the first layer, 20 neurons in the second layer, and one neuron in the output layer. In this test, the neurons in the first layer correspond with the ‘x’ values of the current point along with four previous ‘x’ values from the sine graph. The neuron in the output layer corresponds with the ‘y’ value at the given ‘x’ coordinate that the Neural Network must predict. The activation function for this specific test was chosen as the soft-sign activation function (see Appendix D) because of its output range of negative one to positive one corresponding with the desired output of the sine graph, which has a range from negative to positive one.
Similar to the structure for each Neural Network, the parameters for each learning algorithm were specifically selected for this test. The Neural Network population size of the Genetics Learning Algorithm was set to 500. On the contrary, the learning rate and momentum rate for the Backpropagation Learning Algorithm were set to 4.42510-4and 2.510-14, respectively.
As shown by the bisecting line in Figure 4, both algorithms were unable to predict the values where no training data was given. Instead, the two algorithms simply flattened out, unable to replicate the exact curvature of a sine wave. Despite the lack of prediction accuracy from both learning algorithms, the Backpropagation Learning Algorithm was able to learn the values of the sine graph in which test data was given more accurately than that of the Genetics Learning Algorithm.
The Genetics Learning Algorithm was not able to learn the values of the sine graph to the extent that Backpropagation had accomplished because of its drastic mutations. As the test had shown, the Genetics Learning Algorithm was unable to make finer adjustments within the dendrite weights of the Neural Networks. Due to this difference from the Backpropagation Learning Algorithm, the Genetics Learning Algorithm was unable to replicate the sine graph, and thus, unable to accurately identify the ‘y’ values of the sine graph at any point.
Conclusion
After each test, it can be concluded that the Backpropagation Learning Algorithm is more efficient when it comes to tasks of higher complexity. This is due to the Backpropagation Learning Algorithm’s unique ability to adjust its learning speed allowing the algorithm to regulate its steps towards a lower error. However, the most impactful difference between the two algorithms, which was identified by the reptile classification test, was the presence of overfitting. The Genetics Learning Algorithm was not able to identify the pattern within the data series. Instead, the Genetics Learning Algorithm conformed to the training data it was given and completely ignored the pattern within the data. As hypothesized, the Genetics Learning Algorithm outperformed the Backpropagation Learning Algorithm in situations where the task was of lower complexity.
Limitations
As with any research project, there are limitations to the conclusion. The first limitation was the lack of proper hardware. As this project was done without access to powerful machine learning computers, the speed of each learning algorithm may potentially be skewed. For example, a machine with a larger count of physical processing cores would theoretically be able to calculate the mutations of the Neural Network population within the Genetics Learning Algorithm much faster than the computer used throughout the research project (Gregg, 2013; Richter, 2012; Skeet, 2014). The second limitation of this research project was the programming experience of the researcher. As the researcher is not a professional in the discipline of computer science, the algorithms may not be optimized to their highest capacity. This could potentially result in differing speeds and accuracies of the trained Neural Networks.
Implications
Those limitations standing, the data obtained from the tests could still be implemented in the professional world. When companies are in the process of selecting a learning algorithm to train a Neural Network for a specific task, the data found within this research project will greatly influence their decision. In addition to influencing the learning algorithm selection process, this research project highlights the strengths and weaknesses of each algorithm, which may prove useful to companies or individuals who have already chosen their learning algorithm. For example, given the weaknesses of each learning algorithm, the company or individual will know what complications are apparent when training their Neural Network, further progressing the development of the artificial intelligence used within their application.
Next Steps
Given the implications and limitations of this research project, additional research is needed on the differences between the two algorithms. As one of the limitations was the hardware used to test the learning algorithms, it would be beneficial to test the same concepts on a more capable machine to reinforce the conclusions found through this research project. In addition, further research is required on the Genetics Learning Algorithm, specifically on its efficiency when given differing amounts of training data. This research would be used to identify at what point the Genetics Learning Algorithm starts to overfit the data, which was identified as one of the major differences between the two learning algorithms.
")


{kind=link}