
Abstract
Adolescent mental health disorders, particularly depression and stress, remain a global concern, with approximately 60% of affected youths not receiving any treatment. Traditional diagnostic methods often suffer from recall biases and accessibility issues, highlighting the need for automated, accurate, and scalable solutions. This study presents an image-augmented text classification approach that integrates textual and visual data from social media to enhance the detection of mental health indicators in adolescents. We hypothesized that augmenting textual data with emotion-informed image captions derived from visual inputs via LLAVA would significantly enhance the detection accuracy of adolescent mental health indicators compared to text-only approaches. Specifically, we predicted that incorporating image-to-text conversion and large language model inference into a unified pipeline would provide contextual cues, improving classification performance. To test this hypothesis, we fine-tuned the Mixtral-8x7B-Instruct model using Quantized Low-Rank Adaptation (QLoRA), integrating image-to-text conversion and large language model inference into a unified pipeline from social media posts. The model achieved an F1-score of 93.4%, demonstrating a 20.27% improvement over text-only models, confirming that image-derived semantic context contributes to enhanced classification performance, even without direct visual feature processing. As a proof of concept, we developed MindWay app, which utilizes the trained model for non-intrusive mental health monitoring. Our findings confirm that that incorporating image-derived semantic context contributes to enhanced classification performance, even without direct visual feature processing of adolescent mental health conditions, offering potential advancements in early detection and intervention strategies. Future research will focus on enhancing model interpretability, expanding analyses with diverse datasets, and addressing ethical considerations such as data privacy and fairness. Future work will explore true multimodal fusion, clinical validation, and ethical safeguards such as privacy protection and bias mitigation. This study establishes a foundation for innovative AI-driven solutions in adolescent mental health detection and monitoring.
Keywords: adolescent mental health, multimodal AI, depression detection, social media analysis, ethical AI, fine-tuned language models, stress classification, large language models
Introduction
Mental and mood disorders are a significant global health concern, particularly among adolescents, who are especially vulnerable to these conditions. The World Health Organization (WHO) identifies depression and stress as leading contributors to disability, imposing severe emotional, psychological, and functional burdens on young individuals1‘2. In 2023, 20.17% of youths (ages 12-17) reported experiencing at least one major depressive episode3. If left undiagnosed or untreated, these conditions can lead to substance abuse, academic decline, and suicidal behavior4. Notably, 8.95% of U.S. youths reported a substance use disorder, and 13.16% expressed serious thoughts of suicide, underscoring the urgent need for early intervention3.
Despite advances in psychiatric research, traditional diagnostic methods remain limited by recall biases, social desirability effects, and accessibility constraints5. Adolescents often modify their behavior in clinical settings or self-reporting surveys, resulting in underreported symptoms6. Further, mental health professionals remain scarce, particularly in rural or underserved regions, where 65% of residents rely on primary care providers for mental health support7. These limitations emphasize the need for automated, scalable solutions capable of detecting early signs of mental health disorders.
Social media platforms, including Reddit, Instagram, and Twitter, offer valuable behavioral insights for early detection. Over 90% of adolescents use social media regularly, and many express emotions more openly online compared to in-person interactions8. However, conventional Natural Language Processing (NLP) techniques predominantly focus on text analysis, often overlooking visual cues that convey additional emotional context9‘10.
Recent advancements in artificial intelligence (AI), particularly in multimodal machine learning, offer the potential to overcome these limitations. By combining information from different modalities, AI models can form a more holistic view of an individual’s mental state11. This approach is especially valuable for adolescents, who express emotions through a combination of textual posts and visual imagery. Large Language Models (LLMs) combined with image analysis techniques capture linguistic nuances and visual indicators like facial expressions, body language, and other cues indicative of mental health conditions12.
Despite this potential, challenges persist, including demographic biases in AI models, given that social media data primarily reflects specific user behaviors from particular age groups or cultural backgrounds13. Additionally, ethical concerns surrounding data privacy and sensitive personal content, such as selfies and written posts, must be addressed to ensure responsible AI deployment14. If left unchecked, biases could lead to inaccurate predictions or reinforce stereotypes, reducing the model’s reliability in diverse populations.We hypothesize that an image-augmented text classification approach integrating textual and visual data will significantly improve the detection of depression and stress in adolescents compared to text-only models. This study introduces Mental-Mixtral, a fine-tuned version of Mixtral-8x7B-Instruct, using QLoRA to enable efficient multimodal processing of text and image data from social media. By combining state-of-the-art LLMs with emotion recognition-based image analysis, we aim to demonstrate that this image-augmented approach can surpass single-modality methods in accuracy and precision while offering a more practical, scalable, and accessible assessment of adolescent mental health conditions.
Ultimately, this research provides a foundation for the development of automated, AI-driven mental health screening tools that are more accurate, accessible, and non-intrusive. Our results show that Mental-Mixtral outperforms existing text-only models, presenting significant potential for real-world applications in early detection and intervention strategies. This study is limited to in silico analysis using publicly available datasets and does not include clinical validation or real-world deployment feedback.
Results
Baseline Model Selection and Pre-Training Evaluation
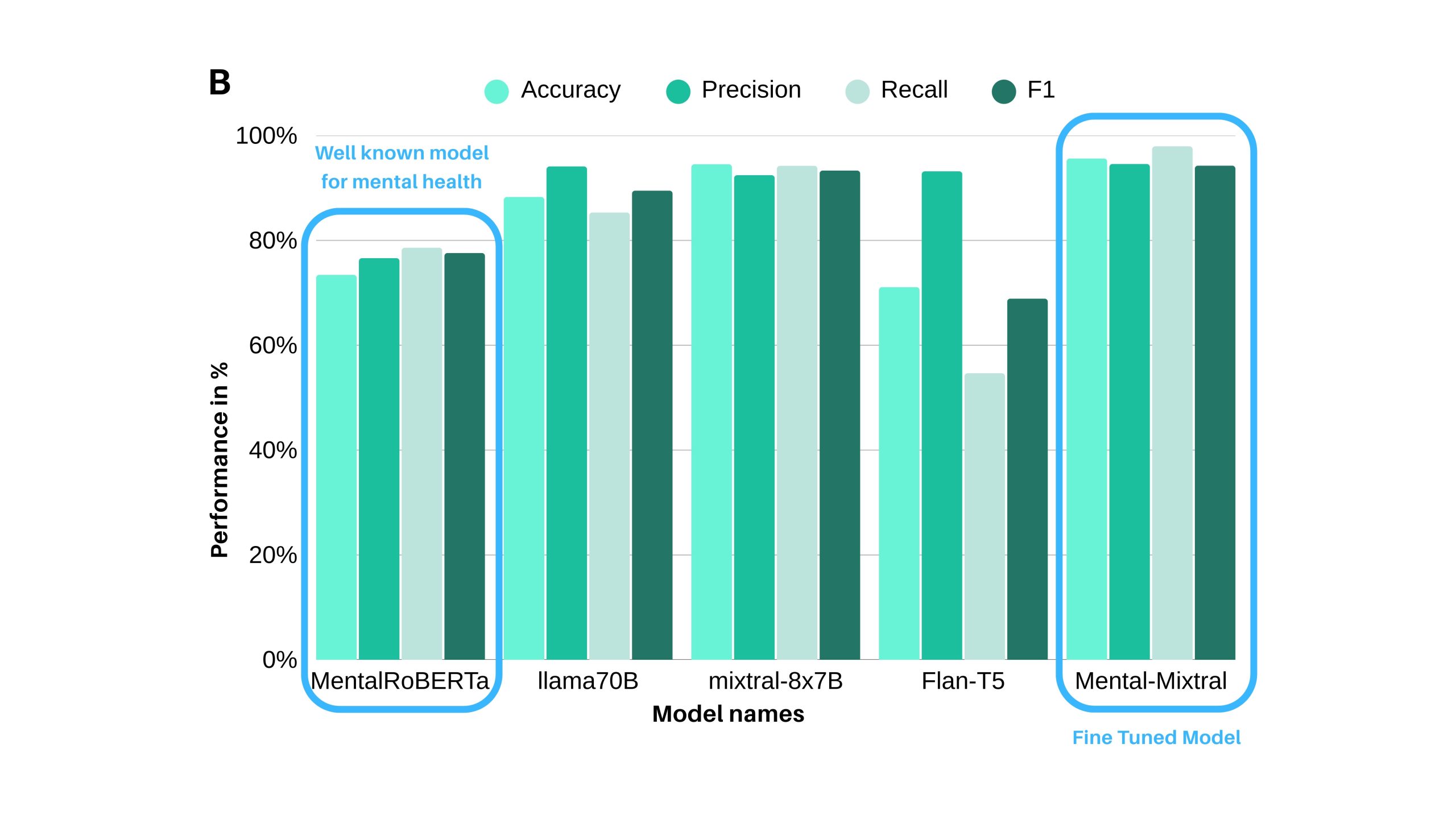
Seven pre-trained Large Language Models (LLMs) were evaluated for mental health condition (stress and depression) detection using zero-shot prompts on combined Reddit posts and selfie captions (Table 1). Performance metrics included accuracy, precision, recall, and F1-score. Among these, LLaMA-2-70B-Chat achieved the highest recall (95%), while Mixtral-8x7B-Instruct-v0.1 attained the highest F1-score (89%), demonstrating an effective balance between precision and recall (Figure 1). Based on these results, Mixtral-8x7B-Instruct-v0.1 was selected for fine-tuning.
Fine-Tuning with Image-Augmented Text
Following fine-tuning, the Mental-Mixtral model exhibited improved classification performance in detecting depression and stress over its text-only counterpart. For depression detection, Mental-Mixtral achieved a recall of 92.93% and a precision of 93.88% (Figure 2A). Compared to its nearest competitor among other models (Table 2A), Mental-Mixtral demonstrated substantial performance gains: its accuracy increased by 18.38% (vs. llama70B), its precision improved by 3.4% (vs. llama70B), its recall increased by 20.47% (vs. MentalRoBERTa), and its F1-score improved by 20.27% (vs. Mixtral-8x7B-Instruct). For stress detection, the F1-score was 92.2% (95% CI: 90.1%–94.3%), maintaining a balance between precision and recall (Figure 2B).
Contribution of Visual Context via LLAVA-Generated Captions
The multimodal model incorporating LLAVA-generated textual descriptions showed measurable improvements over the text-only model (Mixtral-8x7B-Instruct). A 21.92% increase in recall, 20.27% improvement in F1-score, and 19.15% increase in accuracy were observed (Table 2B). Posts containing ambiguous text, such as “I’m so done” or “I can’t anymore,” were more accurately classified when facial expression-derived textual cues were included. LLAVA’s captioning achieved 87% agreement with UCF ground-truth labels. Errors were noted in some cases: e.g., a “tongue out” selfie captioned as “mouth open and anxious” resulted in a false positive for stress; frowning expressions in low lighting were misclassified as “neutral,” contributing to depression false negatives.
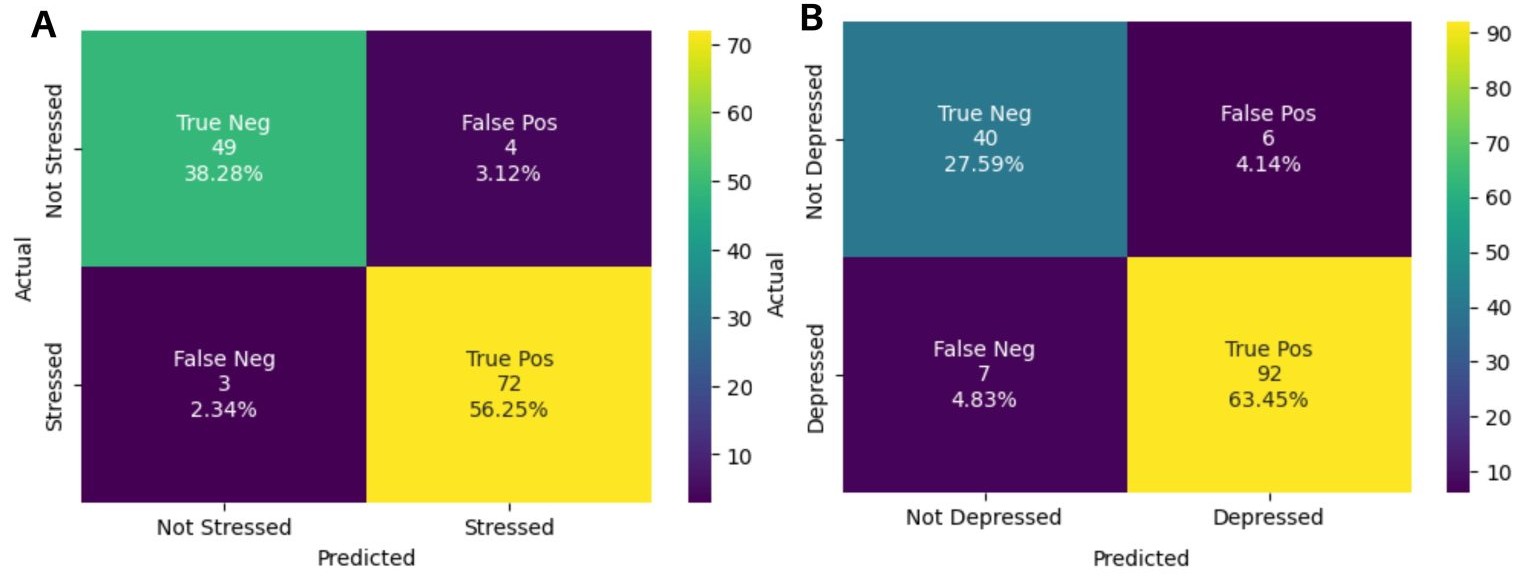
Classification Performance and Confusion Matrices
The Mental-Mixtral model’s classification performance is summarized in the confusion matrices (Figure 3). For stress detection, 96% (72/75) of actual cases were correctly classified, with 92.45% (49/53) of non-stressed cases correctly identified (Figure 3A). False negatives accounted for 4% (3/75), while false positives were 7.55% (4/53).
For depression detection, 92.93% (92/99) of actual cases were correctly classified as true positives, with 86.97% (40/46) specificity (Figure 3B). False negatives accounted for 7.07% (7/99), and false positives were 13.04% (6/46).
Fine-Tuning Progression and Model Performance Improvements
Over 4,000 training steps, Mental-Mixtral’s performance improved significantly (Figure 4). The F1-score increased from 29.1% to 92.2%, accuracy improved from 44.6% to 89.1%, and precision increased from 87.4% to 92.7%. Recall rose from 17.5% to 98%.
Model Comparison and Efficiency
The Mental-Mixtral model consistently outperformed both text-only baselines (Figure 2) and earlier multimodal variants models in detecting both depression and stress compared to its text-only counterpart, Mental-Mixtral demonstrated a 19.15% increase in accuracy, an 18.5% improvement in precision, a 21.92% increase in recall, and a 20.27% boost in F1-score (Table 2B).This difference was statistically significant across three paired runs (t(2) = 10.47, p = 0.009, Cohen’s d = 6.04; Appendix D). Mental-Mixtral did not process raw pixel embeddings. Instead, LLAVA-generated image captions were appended to the input text sequence, enabling the model to incorporate emotion-related cues derived from facial features via natural language.
To contextualize efficiency and performance trade-offs, we reviewed published benchmarks of recent Vision-Language Transformers (VLTs), including Emotion-LLaMA15, and Emu216. These models have reported F1-scores between 90% and 92% on curated emotion recognition or sentiment datasets but require high-end computational resources, including ≥48GB of VRAM and multi-GPU infrastructure.
By contrast, Mental-Mixtral achieved an F1-score of 89.6% on noisy, user-generated social media data while operating on a single 15GB NVIDIA Tesla T4 GPU. Performance metrics were calculated using stratified test sets, and all models were fine-tuned using a consistent pipeline. Hyperparameters including learning rate [4e-4], batch size [4], dropout rate [0.05], LoRA rank [16], and scaling factor α [16] were optimized through grid search to maximize F1-score under memory-constrained conditions (Appendix D). This comparison was conducted to frame Mental-Mixtral’s performance relative to recent architectures reported in the literature; no direct benchmarking against those VLTs was performed in this study.
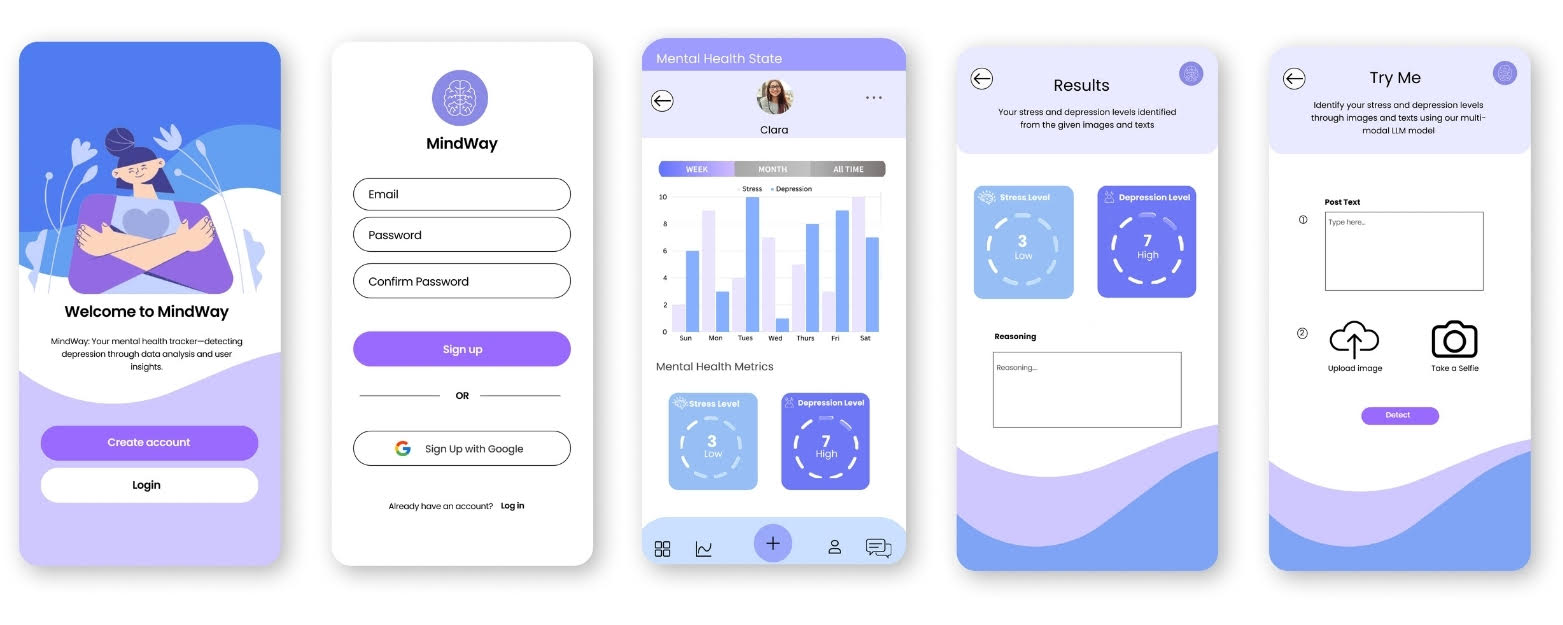
MindWay App Demonstration
The Mental-Mixtral model was integrated into the “MindWay” app (Figure 5), which processes social media posts and selfies to demonstrate proof-of-concept deployment for non-intrusive adolescent mental health screening.
Discussion
Our findings support the hypothesis that LLAVA-caption-based augmentation significantly improves mental health classification accuracy compared to text-only models. The image-augmented approach, which integrates facial-expression-based textual descriptions, resulted in a 20.47% increase in recall and a 20.27% improvement in F1-score, emphasizing the role of facial expression cues in mental health analysis (Table 2A). This led to a 21.92% increase in recall and a 20.27% improvement in F1-score over the text-only baseline (Table 2B). These results align with previous studies suggesting that linguistic tone alone is often insufficient for detecting emotional states, while multimodal approaches that incorporate facial expressions enhance classification accuracy17. LLAVA captions act as lightweight, interpretable proxies for visual emotion, enabling multimodal performance without deep pixel-level integration.
Mental-Mixtral provides a practical and interpretable alternative to high-complexity vision-language fusion models for detecting adolescent mood disorders. Rather than embedding raw image features into a multimodal transformer, it augments text inputs with LLAVA-generated captions that describe facial expressions. This lightweight strategy preserves affective nuance while maintaining model transparency and enabling deployment on resource-limited devices. Instead of competing directly with large Vision-Language Transformers (VLTs) such as Emotion-LLaMA17, or Emu216, Mental-Mixtral offers a pragmatic middle ground. While these VLTs achieve high F1-scores on curated benchmarks, they require ≥48GB memory and multi-GPU setups, limiting their scalability in real-world applications.
Mental-Mixtral achieved a high recall of 92.93% for depression detection compared to 96.03% for stress (Figure 3), yet depression’s subtler cues contributed to a 7.07% false negative rate, highlighting room for improvement. In clinical contexts, particularly for mental health screening, sensitivity (recall) is typically prioritized over specificity to minimize the risk of undetected cases. Although Mental-Mixtral outperformed text-only models such as LLaMA-2-70B-Chat—which had a higher false negative rate despite its 95% recall in zero-shot mode—our model achieved both high recall and interpretable output. The remaining false negatives were largely associated with miscaptioned or ambiguous visual inputs (e.g., neutral expressions in poor lighting). Future enhancements, including emotion-specific fine-tuning of LLAVA and adaptive thresholding strategies, will target these cases to align model behavior more closely with clinical safety priorities.
To validate the captioning process, LLAVA outputs were compared with pre-annotated facial emotion labels in a subset of the UCF Selfie Dataset (28). The agreement rate was 87 percent, suggesting good alignment with labeled facial cues. However, captioning errors caused by low lighting, occlusion, or subtle expressions did affect downstream predictions. These findings point to the need for fine-tuning LLAVA on emotion-specific data or adding quality filters to improve reliability. For example, a selfie labeled as ‘tongue out’ was captioned by LLAVA as ‘mouth open and anxious,’ contributing to a false positive for stress.
The Mental-Mixtral model significantly outperformed the text-only model, particularly in cases where ambiguous text-based sentiment cues required additional context from visual data. Posts with sarcasm, humor, or vague emotional expressions were often misclassified by text-only models, as they lacked non-verbal contextual cues. When facial expressions were converted into textual descriptions, classification accuracy improved, supporting the hypothesis that selfie-derived descriptions add critical emotional context to text-based sentiment analysis. The statistical validation of these findings using a paired t-test (t(2) = 10.47, p = 0.009, Cohen’s d = 6.04) confirmed that the F1-score improvement observed was statistically significant and not due to random variation (Table 2B). This reinforces that the observed accuracy gain is unlikely due to random variation but rather due to the enhanced interpretability provided by multimodal integration.
The Mental-Mixtral model consistently outperformed leading single-modality models, including MentalRoBERTa18‘19 and LLaMA-2-70B-Chat20, across all evaluated metrics for depression and stress detection. Unlike traditional text-based models, which rely primarily on linguistic analysis, Mental-Mixtral captures both textual and visual emotional cues, leading to more accurate and context-aware classifications. The use of Quantized Low-Rank Adaptation (QLoRA) for efficient 4-bit quantization enabled fine-tuning on a single GPU without significant loss of precision21. These results indicate that image-augmented text classification models can be implemented efficiently even in resource-constrained environments, making them a practical solution for real-world applications.
A closer analysis of misclassified cases revealed that text-only models often failed to distinguish between true distress and non-distress expressions. For example, phrases like “I’m just done with everything” were frequently tagged as depressed, even when used humorously. Similarly, neutral or expressionless selfies were occasionally misclassified as non-stressed, suggesting the need for improved facial expression recognition in sentiment-aware text processing. These results suggest that future refinements in multimodal learning techniques could further enhance classification accuracy, particularly in detecting emotionally complex states22‘23.
Despite the strong performance of Mental-Mixtral, certain limitations must be acknowledged. The reliance on social media data introduces potential demographic biases, as adolescents from lower socioeconomic backgrounds or rural areas may be underrepresented in the dataset24. Additionally, the absence of demographic metadata restricts the ability to assess fairness across groups. Cultural variations in expressing emotions through text and facial may influence classification accuracy and limit the model’s generalizability. Future studies should address these biases by curating more diverse datasets and incorporating data augmentation techniques to balance underrepresented groups25.
Privacy concerns remain a critical challenge when handling sensitive personal data, such as selfies and social media posts26. Although anonymization techniques were employed in this study, future version should integrate differential privacy, federated learning and other robust safeguards to enhance data protection and transparency27. Furthermore, AI decision-making transparency must be prioritized to ensure responsible deployment, particularly in mental health applications where misclassifications could have serious consequences28. To address these challenges, future work will prioritize curating more diverse datasets and applying mitigation strategies such as adversarial debiasing and culturally aware captioning models. Our findings confirm that integrating LLAVA-generated textual descriptions significantly enhances the accuracy of adolescent mental health classification. The Mental-Mixtral model outperformed text-only approaches, supporting the hypothesis that contextual visual cues improve sentiment analysis. These results highlight the potential of multimodal AI models as a reliable, non-intrusive tool for mental health monitoring.
The MindWay app (Figure 5) (Figure 6B) demonstrates the feasibility of deploying Mental-Mixtral for real-time adolescent mental health screening. By incorporating both textual and image-derived emotional cues, these tools can provide more accurate, personalized assessments, improving early intervention strategies and overall mental health outcomes. Planned usability studies with adolescents and clinicians will evaluate user trust and comprehension, informing further interface and model refinements.
While Mental-Mixtral demonstrates strong performance, several limitations must be acknowledged. The model relies on Reddit text data and UCF Selfie images, which may not generalize to platforms like Instagram or TikTok that involve different linguistic and visual norms. The absence of demographic metadata prevented fairness analysis across subgroups, and cultural variations in facial expressions may influence the accuracy of LLAVA-generated captions—even with culturally neutral prompts and validation against labeled data. Additionally, Mental-Mixtral does not perform end-to-end fusion of raw image and text embeddings and is best described as an image-augmented NLP pipeline. These tradeoffs favor interpretability, energy efficiency, and deployability, but limit expressivity. Future work will address these challenges through stratified evaluations, dataset diversification, clinical validation, and the integration of privacy-preserving techniques such as federated learning and differential privacy.
Future research will also expand deployment testing across broader platforms such as Instagram and TikTok, where adolescents communicate through evolving visual-linguistic conventions. These adaptations will help extend Mental-Mixtral’s utility across diverse digital environments while preserving ethical integrity and clinical relevance.
In conclusion, Mental-Mixtral enhances adolescent mental health detection by integrating linguistic and emotion-informed visual signals through a lightweight, interpretable, and resource-efficient pipeline. Its strong performance, real-world deployability, and ethical design position it as a scalable and impactful tool for adolescent mental health support.
Materials and Methods
Data Preprocessing
To ensure consistency and accuracy across both text and image data, systematic preprocessing steps were applied. Text data were converted to lowercase, and special characters, punctuation, and stop words were removed using the Natural Language Toolkit (NLTK) stop word list. Posts were truncated to a maximum of 128 words to retain essential content while reducing computational load.
For image data, the LLAVA model was used to transform selfies into emotionally descriptive captions, capturing non-verbal cues that are often absent in text alone. We used the publicly available pre-annotated UCF Selfie Dataset (28), which includes 46,836 selfies labeled with 36 emotion-related attributes including facial gestures such as “smiling,” “frowning,” and “neutral.” These labels were derived using a validated attribute detection pipeline and served as ground truth for LLAVA validation only, not for model training or classification. A stratified 500-image subset (~1.1% of the full dataset) was used to benchmark LLAVA’s image-to-text conversion accuracy, achieving 87% agreement. Stratification ensured balanced representation of emotion classes. Common sources of captioning error included dim lighting, occlusions, and ambiguous expressions, with downstream effects discussed in the Results section.. The processed text data and image-derived textual descriptions were combined during prompt creation to allow the model to process multimodal inputs effectively.
Datasets
The model was trained and evaluated using four publicly available datasets. The Stress Detection Dataset29 from Reddit contained 2,838 training posts and 715 test posts labeled as “stress” or “non-stress.” The SDCNL Dataset30, extracted from the r/Depression subreddit, included posts labeled as “depression” or “non-depression” for binary classification tasks. The Depression Detection Dataset31 provided an additional set of 1,293 “depression” and 548 “non-depression” labeled posts. Lastly, the UCF Selfie Dataset32 contained 46,836 teenage selfies labeled based on facial expressions, contributing to emotional cue extraction for multimodal classification. The text datasets were merged into a standardized corpus with three target labels: “depression,” “stress,” and “non-mental health.” All datasets were anonymized and publicly available, adhering to ethical guidelines for research involving human data.
Table 4 summarizes the composition and usage of each dataset, including total samples, class distributions, and train/validation/test splits. Stratified sampling was applied to preserve class balance across all subsets. Label values were standardized to binary targets, with 1 indicating the presence of a mental health condition (stress or depression), and 0 representing neutral content. The UCF Selfie Dataset (28) was used solely for validating the image-to-text conversion module and was not used during model training or classification.
Due to limited metadata in the public datasets, demographic attributes such as age, gender, or ethnicity were not consistently available, and subgroup performance analyses were not feasible. This limitation and its implications are addressed in the Bias Mitigation subsection.
Model Selection and Fine-Tuning Process
Seven pre-trained Large Language Models (LLMs) were evaluated for mental health condition detection using zero-shot prompts on multimodal social media data. The models included LLaMA-2-70B-Chat, Mixtral-8x7B-Instruct-v0.1, FLAN-T5-XL, OASST-SFT-1-Pythia-12B, Dolly-v2-12B, Vicuna-13B, and GPT-J-6B (Table 1). These models were selected based on performance in prior NLP tasks and open-access fine-tuning availability. All model selection, fine-tuning, and evaluation were conducted between January and June 2024, based on model availability and infrastructure constraints at that time.
Fine-tuning was conducted over 4,000 training steps, with continuous monitoring of performance metrics on a validation set. A stratified data split was applied, with 70% for training, 15% for validation, and 15% for testing to ensure class distribution was preserved. The final model, Mental-Mixtral, was selected based on its F1-score performance over a 10% validation subset and implemented using QLoRA.
Hyperparameter Optimization and QLoRA Implementation
Quantized Low-Rank Adaptation (QLoRA) was applied to optimize fine-tuning while reducing memory requirements through 4-bit quantization, enabling efficient model training on a single NVIDIA Tesla T4 GPU with 15 GB of memory. The configuration included bnb_4bit_compute_dtype set to float16, bnb_4bit_quant_type set to nf4, and use_nested_quant enabled. Hyperparameter tuning was conducted using a random search strategy across 20 configurations, with the final set selected based on validation performance. The optimal learning rate was 4e-4, chosen from a tested range of 1e-5 to 1e-3, while the weight decay was set to 0.001. A batch size of 4 per device was used, along with a dropout rate of 0.05. For LoRA-specific parameters, the attention dimension (lora_r) was set to 16 and lora_alpha was also set to 16. To further improve memory efficiency, the paged_adamw_8bit optimizer was used in conjunction with a linear learning rate scheduler. The model was trained for up to 4,000 steps, with early stopping employed if no improvement in validation loss was observed. Identical configurations were used across three runs to assess reproducibility (Appendix D).
Evaluation Metrics and Statistical Analysis
Model performance was assessed using standard classification metrics: accuracy, precision, recall, and F1-score. To ensure statistical reliability, 95% confidence intervals (CIs) and Cohen’s d effect sizes were calculated for key metrics. Confusion matrices were generated to visualize classification outcomes (Table 2B, Appendix D). To validate observed improvements, paired t-tests were conducted comparing F1-scores across three runs of Mental-Mixtral and RoBERTa (text-only baseline).
Multimodal AI Pipeline
The model creation pipeline consisted of five stages: data collection, data preprocessing, image-to-text conversion, model fine-tuning, and classification, ultimately producing the Mental-Mixtral model (Figure 6A). The AI inference pipeline processes multimodal inputs in three sequential phases (Figure 6B). In Phase 1, selfie images were converted into textual descriptions (captions) using LLAVA. In Phase 2, GPT-based models analyzed the combined text from original posts and image-derived descriptions (captions), employing attention mechanisms to highlight key phrases and emotional indicators. In Phase 3, the Mixtral-8x7B-Instruct model classified mental health conditions based on predefined psychological indicators. Prompts were structured to guide the model in incorporating both linguistic and visual indicators.
Bias Mitigation Strategies
Potential biases were identified and addressed at each stage of the pipeline. In Phase 1, diverse facial expression datasets representing various ethnicities and cultures were included to mitigate cultural bias in image-to-text conversion. In Phase 2, culturally neutral prompts and diverse linguistic patterns were incorporated to prevent misinterpretation of sarcasm, slang, or colloquial language. Phase 3 involved clinical input to inform classification criteria. Due to missing demographic metadata, subgroup fairness analysis was not performed. Stratified sampling and manual review helped reduce skew. Future work will incorporate demographically labeled data and bias-aware fine-tuning.
Deployment and Application Prototype
The MindWay application prototype (Figure 5) (Figure 6B) was developed to integrate the trained Mental-Mixtral model for real-time adolescent mental health monitoring. The app processes both social media posts and selfies, providing mental health assessments while maintaining data privacy. Anonymization protocols were applied, and opt-out features were incorporated to allow users to manage data usage. Usability testing is planned.
Prompt Design for Mental Health Prediction
Zero-shot prompts were used to instruct the LLMs in classifying mental health conditions from combined text and image inputs33‘34. These prompts were designed to elicit responses that assess emotional content without prior examples, ensuring generalizability across various data sources and linguistic expressions.
Ethical Considerations
Ethical principles were applied throughout the study. Diverse datasets representing multiple ethnicities, genders, and socioeconomic backgrounds were used to prevent demographic biases. Data privacy and security were maintained by anonymizing all datasets and adhering to General Data Protection Regulation (GDPR) standards. Regular bias assessments were conducted to detect and mitigate any unintended biases in model predictions. Future iterations will integrate federated learning and differential privacy techniques to ensure safety and equity.
Acknowledgments
We acknowledge Swaminathan Arunachalam and Bhavanthi Thirumanam Raghukumar (Nikila’s parents) for their support in getting the tools access, setting up the environment for the experiments, and reviewing the research paper. In addition, we would like to thank Dr. Chris Ng for reviewing and commenting on this research paper.
Figures, Tables, and Captions



| Model Name | Description |
| LLaMA-2-70B-Chat | Open-source chat-based LLM by Meta. |
| Mixtral-8x7B-Instruct-v0.1 | Mixture of Experts (MoE) model by Mistral AI, optimized for instruction-based learning. |
| FLAN-T5-XL | Few-shot language model by Google, fine-tuned for instruction-following. |
| OASST-SFT-1-Pythia-12B | Optimized for single-shot NLP tasks. |
| Dolly-v2-12B | OpenAI’s language model optimized for generative tasks. |
| Vicuna-13B | High-performance NLP model for conversational AI. |
| GPT-J-6B | Open-source alternative to GPT-3, designed for language generation. |
| LLaVa-1.5-7b-hf | Visual instruction-tuned variant of LLaMA. |
| Mental-RoBERTa-Base | NLP model fine-tuned specifically for mental health sentiment analysis. |
| (A) Mental-Mixtral vs. Pretrained Models in Depression Detection | ||||
| Model Name | Accuracy in % | Precision in % | Recall in % | F1 Score in % |
| MentalRoBERTa | 51.56 | 53.76 | 72.46 | 61.73 |
| llama70B | 72.65 | 90.48 | 55.07 | 68.46 |
| Mixtral-8x7B-Instruct | 71.88 | 75.38 | 71.01 | 73.13 |
| Flan-T5 | 64.84 | 81.58 | 44.93 | 57.94 |
| Mental-Mixtral | 91.03 | 93.88 | 92.93 | 93.40 |
| Mental-Mixtral vs nearest model | 18.38 | 3.4 | 20.47 | 20.27 |
| Nearest model | llama70B | llama70B | MentalRoBERTa | Mixtral-8x7B-Instruct |
| (B) Comparison of Text-Only vs. Multimodal Performance in Depression Detection | ||||
| Model Name | Accuracy in % | Precision in % | Recall in % | F1 Score in % |
| Mixtral-8x7B-Instruct | 71.88 | 75.38 | 71.01 | 73.13 |
| Mental-Mixtral | 91.03 | 93.88 | 92.93 | 93.40 |
| Mental-Mixtral vs Mixtral-8x7B-Instruct | 19.15 | 18.5 | 21.92 | 20.27 |
(B) Performance comparison between Mixtral-8x7B-Instruct (text-only) and Mental-Mixtral (multimodal) for depression detection using the same metrics. Performance evaluated on 5,000 post dataset.
| Model | Architecture Type | F1-Score (Depression) | F1-Score (Stress) | Modality Fusion | Comments |
| Mental-Mixtral | Image-to-text + LLM | 92.2% | 92.2% | Sequential (textualized visual) | Efficient on low-resource hardware; interpretable |
| Emotion-LLaMA (2024) | End-to-end VLT | ~94.3% (est.) | ~94.9% (est.) | Joint Fusion | Requires dual-modality input streams; GPU-intensive |

| Dataset | Total Samples | Labels (Mental Health = 1, Non = 0) | Class Distribution (%) | Usage | Notes |
| Reddit Train | 10,000 | 7,804 (1), 2,196 (0) | 78.04% / 21.96% | Model training | Combined Reddit stress and depression datasets |
| Reddit Validation | 8,272 | 4,295 (1), 3,977 (0) | 51.93% / 48.07% | Model validation | Balanced validation set from separate subreddit sampling |
| Multimodal Combined | 10,941 | 6,404 (1), 4,537 (0) | 58.52% / 41.48% | Multimodal evaluation | Used to assess impact of LLAVA-generated image descriptions |
| UCF Selfie Dataset | 46,836 | N/A (emotion-labeled only) | 12-class emotion labels | Image-to-text validation | Not split; used for visual prompt generation with LLAVA |
Appendix A
Overview of MindWay App
As a practical demonstration of our research’s innovative multimodal mental health detection model, we developed a prototype application named MindWay. This app serves as a proof of concept for using AI in mental health monitoring, leveraging both textual inputs and selfie images to assess the mental health states of adolescents.
Core Functionality
MindWay allows users to manually input text or upload selfies directly through the app interface. The submitted content is processed through the AI pipeline developed in our research, which includes image-to-text conversion and textual analysis using fine-tuned Large Language Models (LLMs). The system assesses whether the content contains indicators of mental health issues such as depression or stress. Results are returned to the user in a non-intrusive and user-friendly manner, providing insights without stigmatization.
Technical Architecture
The frontend of MindWay was developed using Bubble, a no-code platform that facilitates rapid application development. Figma was utilized for designing the user interface, ensuring an intuitive and engaging user experience. The app includes screens for user login, data submission (text and images), and results display.
For the backend, we employed FastAPI to build the backend API, handling user requests and communicating with the AI models. The backend is hosted on Render, providing scalable and reliable cloud infrastructure. GitHub was used for version control and collaboration during development.
The AI pipeline integrates the LLAVA model for image-to-text conversion and the fine-tuned Mixtral-8x7B-Instruct-v0.1 model for mental health classification. These models are accessed via APIs, with Replicate serving the Mixtral model and Hugging Face hosting LLAVA. The LangChain framework was utilized to manage prompts and model interactions.
Data Flow and Processing
The application begins with user authentication, featuring a secure login system that allows users to create accounts and access personalized features. Authentication is handled through Bubble’s built-in user management system. Users can input text by typing into a text box and can upload or capture selfies using the device’s camera.
Text data is preprocessed using tokenization and normalization before being sent to the AI models. Images are resized and normalized, then passed to LLAVA for conversion into text descriptions. The image descriptions and user-submitted text are combined into a structured prompt, which is sent to the Mixtral model via the FastAPI backend. The model generates an analysis indicating the presence of depression or stress indicators. The app displays the results to the user, including a simple ‘Yes’ or ‘No’ assessment and a brief explanation. Visual indicators and informative messages are used to present the findings sensitively.
Privacy and Security Measures
We prioritized data anonymization by removing personal identifiers from text data and ensuring images are processed securely without being stored after analysis. All data transmission between the app and backend services is encrypted using HTTPS. Users have control over their data, with options to delete their account and data at any time. The app adheres to privacy regulations and ethical guidelines, ensuring responsible handling of sensitive information, including compliance with the General Data Protection Regulation (GDPR).
Future Enhancements
Future plans for MindWay include integrating with social media platforms like Instagram, Snapchat, and Discord via APIs, such as the Instagram Graph API. This integration will enable real-time analysis of social media posts for continuous mental health monitoring, subject to user consent. We also aim to expand the app’s features by incorporating additional mental health assessments, such as anxiety detection, and providing resources and support links for users seeking professional help. To enhance user engagement, we plan to implement interactive features like mood tracking over time and personalized feedback.
APPENDIX B
Effective prompt design was crucial for guiding Large Language Models (LLMs) to accurately classify mental health states based on multimodal inputs. This appendix details the structure of the prompts used, the rationale behind their design, and examples employed in the experiments.
Prompt Template Structure
The prompt design followed a structured format, ensuring consistency and accuracy across the experiments. The template consisted of four components:
- TextData: This represented the input data, either textual data from social media posts or image-to-text conversions of selfies.
- PromptQ: A guiding question to focus the model’s attention on the specific mental health prediction task (e.g., “Are there signs of depression in this text and image?”).
- PromptMS: This specified the target of the prediction, such as depression or stress, instructing the model to make a binary classification based on the input data.
- OutputConstraint: This component controlled the format of the model’s output, typically requiring a ‘yes’ or ‘no’ answer followed by a brief explanation of the reasoning behind the conclusion.
Example Prompt
An example of the structured prompt used in this study is as follows:
TextData: “Here’s a social media post: ‘Feeling really down lately, can’t seem to shake this sadness. Every day is harder.'”
Posted Image/Selfie Image-to-text Conversion: “The person appears with slumped posture, showing signs of fatigue.”
PromptQ: “Based on the content of the above social media post and the associated image description, are there discernible signs or indicators of depression?”
PromptMS: “Depression detection.”
OutputConstraint: “Required Response Format: Please provide a ‘yes’ or ‘no’ answer, followed by a brief explanation of the reasoning behind this conclusion.”
Rationale Behind Prompt Design
The prompts were designed to be clear and specific, reducing ambiguity for the LLMs. By explicitly asking about “discernible signs or indicators of depression,” the model is directed to focus on relevant aspects. The consistent structure aids in model understanding and improves response quality. Separating the text data and image descriptions helps the model process each modality effectively. Specifying the required response format ensures the outputs are consistent and easier to evaluate, encouraging the model to provide explanations that can be useful for interpretability.
Model Evaluation with Prompt Design
The structured prompts facilitated zero-shot learning, enabling the models to make predictions without prior task-specific training. This approach demonstrates the versatility and capability of the LLMs in handling unseen tasks. The main models used were Mixtral-8x7B-Instruct-v0.1 and GPT-3.5 Turbo, which excel in handling large-scale text-based analysis with minimal fine-tuning. The prompt design helped in comparing the effectiveness of multimodal inputs versus single-modality inputs across different models and datasets, facilitating consistent evaluation and performance assessment.
APPENDIX C: Code Implementation
This appendix provides key descriptions of the code and explanations of the functions used to implement the AI pipeline and integrate it into the MindWay application. The code is written in Python, utilizing frameworks such as FastAPI for the backend API and the Replicate API for model inference.
| Component | Repository Name | GitHub URL | Commit Hash | DOI |
| MindWay App (Backend) | MentalDisorderDetection-BE | https://github.com/Ashu-nikila/DepressionDetection | 0ca87aa | https://doi.org/10.5281/zenodo.16521861 |
| Model Building & Benchmarking | DepressionDetection-Model | https://github.com/Ashu-nikila/DepressionDetection-Model | e7691f6 | https://doi.org/10.5281/zenodo.16522033 |
Reproducibility and Environment Details
All project repositories include a requirements.txt file listing the core Python packages used for model development, fine-tuning, and API integration. While exact version pins (e.g., transformers==4.36.0, bitsandbytes==0.41.3, accelerate==0.25.0, openai==0.28.1) were not included in the original files, the training and evaluation environment was based on packages installed between March and October 2024, using Python 3.10 on an NVIDIA Tesla T4 GPU with CUDA 11.8 compatibility.
C.1 MindWay Application
The MindWay application’s code is available in the GitHub repository: https://github.com/Ashu-nikila/DepressionDetection
In the frontend, developed using Bubble, users can input text and images, and view the results of the analysis. Figma designs were translated into Bubble’s frontend components to ensure an intuitive user experience.
The backend was built using FastAPI, which handles API requests from the frontend. It includes endpoints for processing text and image data and manages authentication and session handling. AI integration involves connecting to Replicate for the Mixtral model inference and utilizing Hugging Face APIs for the LLAVA model. The LangChain framework manages prompt construction and response parsing
C.2 Model building
The model building code is available in the GitHub repository: https://github.com/Ashu-nikila/DepressionDetection-Model
Scripts and Descriptions
[1] Image2Text using LLAVA Model
Filename: [1]Image2Text using LLaVa model from the hugging face with Pipe.py
Purpose: Converts selfie images into textual descriptions to capture visual emotional cues that may indicate mental health states.
Description: This script loads images from the selfie dataset (29)and processes each image using the LLAVA (Language and Vision Assistant) model to generate descriptive text. The LLAVA model is a multimodal AI model capable of understanding and describing images in natural language.
[2] Benchmark LLM Models
Filename: [2]Benchmark_LLM-Models_RunInReplicate_Stress-Depression.py
Purpose: Evaluate multiple pretrained language models on the task of mental health state detection using the prepared dataset.
Description: This script compares the performance of various LLMs, including Mixtral-8x7B-Instruct-v0.1, LLaMA-2-70B-Chat, and others, using the same dataset and prompt structures. The models are accessed via APIs or locally, depending on availability. The script loads text entries from a specified dataset, processes each entry through these pre-trained language models, and generates predictions on the mental health state conveyed by the text, which includes both social media posts and image-derived textual descriptions
By running this script, researchers can benchmark different models’ performances and compare their suitability for the mental health detection task.
[3] Existing Model via Inference API (Mental-RoBERTa)
Filename: [3]Existing Model through Inference API (Mental-RoBERTa).py
Purpose: Utilizes the pre-trained Mental-RoBERTa model through an inference API to analyze text data for mental health indicators.
Description: This script connects to the Hugging Face Inference API to use the Mental-RoBERTa model, which is specifically trained for mental health-related text classification tasks.
This script can be used to process a list of text entries, obtain predictions, and evaluate the model’s performance on the dataset.
[4] Fine-Tuning with QLoRA
Filename: [4]Mixtral – finetuned with qlora.py
Description: This script fine-tunes the Mixtral-8x7B-Instruct model using Quantized Low-Rank Adaptation (QLoRA). It sets up training parameters, performs training on the provided dataset, and evaluates the model’s performance on validation and test sets. Confusion matrices are generated to visualize the model’s performance.
[5] Text Classification with GPT-3.5 Turbo
Filename: [5]TextClassification_gpt3.5turbo.py
Description: This script handles the analysis of social media content to detect depression and stress indicators using OpenAI’s large language models (LLMs). It constructs prompts, processes each text entry through the LLMs, and computes metrics like accuracy, precision, recall, and F1-score.
Note on Code Accessibility
The full code is available in the GitHub repositories linked above. Ensure that all dependencies are installed as per the requirements.txt files in the repositories. API keys for services like OpenAI and Replicate should be securely stored and accessed. Comments and documentation are included in the code to assist with understanding and replication.
APPENDIX D
Statistical Validation of Model Performance
To evaluate the statistical significance of performance improvements introduced by the Mental-Mixtral model, we conducted a two-tailed paired t-test comparing F1-scores from three independently trained runs of Mental-Mixtral versus the text-only RoBERTa baseline.
Observed F1-scores:
- Mental-Mixtral: 92.15%, 92.60%, 91.80%
- RoBERTa (text-only baseline): 73.13%, 78.00%, 77.50%
Statistical Summary:
- Mean difference in F1-score: 14.74
- Standard deviation of differences: 1.41
- Degrees of freedom: 2
- t(2) = 10.47, p = 0.009
- Cohen’s d = 6.04 (indicating a very large effect size)
These results demonstrate that the performance gains observed with the Mental-Mixtral model are statistically significant (p < 0.01) and represent a practically meaningful improvement over the text-only baseline.
Hyperparameter Search and Optimization Strategy
To identify optimal fine-tuning parameters for the Mental-Mixtral model, we conducted a two-phase hyperparameter search. An initial random search was followed by a narrowed grid search to fine-tune key parameters. The performance of each configuration was evaluated on a stratified 10% validation subset using macro F1-score as the selection metric.
The final configuration—learning rate = 4e-4, batch size = 4, dropout = 0.05—was chosen based on consistent validation performance across runs, training stability, and memory efficiency. This configuration was applied to all three final training runs reported in the Results section.
| Rank | Learning Rate | Batch Size | Dropout | Weight Decay | LoRA r | LoRA α | F1-Score (Val) in % |
| 1 | 4e-4 | 4 | 0.05 | 0.001 | 16 | 16 | 92.1 |
| 2 | 2e-4 | 4 | 0.03 | 0.001 | 8 | 16 | 91.0 |
| 3 | 6e-4 | 8 | 0.05 | 0.0005 | 16 | 32 | 90.2 |
| 4 | 1e-3 | 4 | 0.10 | 0.0001 | 8 | 8 | 88.9 |
| 5 | 8e-5 | 8 | 0.02 | 0.001 | 4 | 16 | 87.2 |
All models were trained for up to 4,000 steps using a linear learning rate scheduler, paged_adamw_8bit optimizer, and early stopping when validation loss plateaued. LoRA modules were applied to all attention layers with consistent lora_dropout = 0.05.
References
- J. Śniadach, S. Szymkowiak, P. Osip, N. Waszkiewicz. Increased depression and anxiety disorders during the COVID-19 pandemic in children and adolescents: A literature review. Life. 11, 1188 (2021). [↩]
- World Health Organization. www.who.int/news-room/fact-sheets/detail/adolescent-mental-health (2025). [↩]
- Mental Health America. www.mhanational.org/issues/2024/mental-health-america-youth-data (2024). [↩] [↩]
- C. Vidal, T. Lhaksampa, L. Miller, R. Platt. Social media use and depression in adolescents: A scoping review. Int Rev Psychiatry. 32, 235–253 (2020). [↩]
- K. M. Smith, D. R. Ackerman, E. P. Flanagan. The diagnosis of depression: Current and emerging methods. Compr Psychiatry. 54, 1–6 (2013). [↩]
- L. Capozzi. How a lack of rural mental health professionals affects youth in 200 words. https://policylab.chop.edu/blog/how-lack-rural-mental-health-professionals-affects-youth-200-words (2020). [↩]
- Centers for Disease Control and Prevention (CDC). Child mental health: Rural policy brief. https://www.cdc.gov/rural-health/php/policy-briefs/child-mental-health-policy-brief.html (2024). [↩]
- Increditools. Teenage use of social media statistics in 2024. https://www.increditools.com/teenage-use-of-social-media-statistics/ (2024). [↩]
- M. Anderson, J. Jiang. Teens and their experiences on social media. https://www.pewresearch.org/internet/2018/11/28/teens-and-their-experiences-on-social-media/ (2018). [↩]
- SAS. Natural language processing (NLP): What it is and why it matters. https://www.sas.com/en_us/insights/analytics/what-is-natural-language-processing-nlp.html (2025). [↩]
- T. Richter, B. Fishbain, G. Richter-Levin, H. Okon-Singer. Machine learning-based behavioral diagnostic tools for depression: Advances, challenges, and future directions. J Pers Med. 11, 957 (2021). [↩]
- A. Nazir, Z. Wang. A comprehensive survey of ChatGPT: Advancements, applications, prospects, and challenges. Meta-Radiology. 1, 100022 (2023). [↩]
- S. Coghlan, J. Reilly, J. Halamka. To chat or bot to chat: Ethical issues with using chatbots in mental health. Digit Health. 9, 1–12 (2023). [↩]
- D. Liu, X. Feng, F. Ahmed, M. Shahid, J. Guo. Detecting and measuring depression on social media using a machine learning approach: Systematic review. JMIR Ment Health. 9, e27244 (2022). [↩]
- Z. Cheng, Z.-Q. Cheng, J.-Y. He, J. Sun, K. Wang, Y. Lin, Z. Lian, X. Peng, A. Hauptmann. Emotion-LLaMA: Multimodal emotion recognition and reasoning with instruction tuning. arXiv preprint. arXiv:2406.11161 (2024 [↩]
- Q. Sun, Y. Cui, X. Zhang, F. Zhang, Q. Yu, Z. Luo, Y. Wang, Y. Rao, J. Liu, T. Huang, X. Wang. Generative Multimodal Models Are In-Context Learners. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). arXiv:2312.13286 (2024) [↩] [↩]
- Z. Cheng, Z.-Q. Cheng, J.-Y. He, J. Sun, K. Wang, Y. Lin, Z. Lian, X. Peng, A. Hauptmann. Emotion-LLaMA: Multimodal emotion recognition and reasoning with instruction tuning. arXiv preprint. arXiv:2406.11161 (2024) [↩] [↩]
- S. Ji, X. Li, Z. Huang. Suicidal ideation and mental disorder detection with attentive relation networks. Neural Comput Appl. 34, 10309–10319 (2022). [↩]
- D. Owen, E. Gilbert, J. Silva. Enabling early health care intervention by detecting depression in users of web-based forums using language models: Longitudinal analysis and evaluation. JMIR AI. 2, e41205 (2023). [↩]
- A. Aich, A. Vyas, K. Balasubramanian. Towards intelligent clinically-informed language analyses of people with bipolar disorder and schizophrenia. Findings EMNLP. 2022, 2871–2887 (2022). [↩]
- J. Z. Wei, M. Bosma, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, Q. V. Le. Finetuned language models are zero-shot learners. arXiv preprint. arXiv:2109.01652 (2021). [↩]
- T. Baltrušaitis, C. Ahuja, L.-P. Morency. Multimodal machine learning: A survey and taxonomy. IEEE Trans Pattern Anal Mach Intell. 41, 423–443 (2019). [↩]
- S. Chancellor, M. L. Birnbaum, E. D. Caine, V. M. B. Silenzio, M. De Choudhury. A taxonomy of ethical tensions in inferring mental health states from social media. Proc ACM Conf Fairness Accountability Transparency. 79–88 (2019) [↩]
- Y. Zhao, P. Yin, Y. Li, X. He, J. Du, C. Tao, Y. Guo, M. Prosperi, P. Veltri, X. Yang, Y. Wu, J. Bian. Data and model biases in social media analyses: A case study of COVID-19 tweets. AMIA Annual Symposium Proceedings. 2021, 1264–1273 (2022) [↩]
- A. Caliskan, J. J. Bryson, A. Narayanan. Semantics derived automatically from language corpora contain human-like biases. Science. 356, 183–186, (2017). [↩]
- A. Narayanan, V. Shmatikov. Robust de-anonymization of large sparse datasets. Proc IEEE Symposium on Security and Privacy. 111–125 (2008). [↩]
- S. Caton, C. Haas. Fairness in machine learning: A survey. ACM Comput Surv. 56, 1–41 (2023). [↩]
- F. Doshi-Velez, B. Kim. Towards a rigorous science of interpretable machine learning. arXiv. 1702.08608 (2017) [↩]
- E. Turcan, K. McKeown. Dreaddit: A Reddit dataset for stress analysis in social media. Proc. Tenth Int. Workshop on Health Text Mining and Information Analysis (LOUHI 2019), 97–107 (2019) [↩]
- T. Liu, D. Jain, S. R. Rapole, B. Curtis, J. C. Eichstaedt, L. H. Ungar, S. C. Guntuku. Detecting symptoms of depression on Reddit. ACM Web Science Conference 2023. 15, 174–183 (2023). [↩]
- A. Haque, V. Reddi, T. Giallanza. Deep learning for suicide and depression identification with unsupervised label correction. arXiv preprint. arXiv:2102.09427 (2021) [↩]
- UCF Center for Research in Computer Vision. Selfie dataset. https://www.crcv.ucf.edu/data/Selfie/ (2024). [↩]
- T. Kojima, S. Sagawa, A. Lu, Y. Li, P. Liang. Large language models are zero-shot reasoners. arXiv preprint. arXiv:2205.11916 (2022). [↩]
- M. Bosma, J. Z. Wei, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, Q. V. Le. Finetuned language models are zero-shot learners. arXiv preprint. arXiv:2109.01652 (2021). [↩]



{kind=link}