
Abstract
Language barriers prevent immigrants from finding employment, thriving socially, and obtaining quality healthcare. Furthermore, many are embarrassed by and even mocked because of poor pronunciation. Therefore, good pronunciation is critical for bridging language barriers and increasing confidence. For Mandarin speakers, the second largest language group in the world, linguistic differences make learning English pronunciation particularly difficult: English is alphabetic and stress-timed, while Mandarin is logographic and syllable-timed. Pronunciation is even more challenging for elderly learners, who experience age-related cognitive decline and memory loss. In my community work with senior Chinese immigrants learning English, I observed that learners often use Mandarin characters to represent the sounds of English words. This ad hoc method leverages familiar characters to aid memory but often fails to accurately capture the English pronunciation. Thus, I propose an AI solution that systematically converts English words into phonetically similar Mandarin characters, enhanced with visual cues to improve pronunciation accuracy. This approach incorporates font size variations to denote stress patterns and highlights phoneme substitutions to provide corrective feedback. A pilot study using large language models (LLMs) and Microsoft Azure Speech Services demonstrated feasibility and results from preliminary testing showed promising improvements in pronunciation accuracy, suggesting this approach can empower users to overcome language barriers and foster greater confidence and well-being.
Keywords: AI, pronunciation, Mandarin, English language learning, elderly, immigrants, large language models (LLM)
Introduction
Problem and Literature Review
For many immigrants, language barriers are a significant challenge to overcome when assimilating into their new communities. Language barriers affect immigrants’ access to healthcare1,2, opportunities for employment3, social life4, dependence on family5, and more. Generally, spoken language is taught with the goals of knowing the correct grammar and having good pronunciations of English words. Both of these components are essential to language acquisition, but pronunciation is more critical when bridging the language barrier because it most directly affects one’s intelligibility6. Mispronounced words can easily cause miscommunication and can result in embarrassment, humiliation, and mockery7,8.
To obtain native-like pronunciation, English for Speakers of Other Languages (ESOL) learners are often first taught the English phonemes and given exercises to practice them9. However, research has shown that it becomes much more difficult for adult ESOL learners to pick up the sound system than younger learners because of greater native language interference10. This particularly affects older ESOL learners’ pronunciation, as it is difficult for them to hear and replicate the phonemes that they have not encountered before11. There are even more challenges for elderly ESOL learners who are struggling with poor memory, deteriorating eyesight, and slow response time12. Is there a more effective way of learning English for elderly ESOL learners? To explore this question, I will hone in specifically on elderly Chinese immigrants in NYC Chinatown. As a volunteer with the Chinatown Literacy Project (CLP) that helps elderly English learners correct their pronunciation, I have found that it is particularly challenging for Mandarin speakers to learn English pronunciation. As research by Zhang and Yin10 has shown, these challenges include: the absence of certain phonemes, the existence of a similar sound that is not accurate, the lack of consonant clusters in Mandarin, the accidental articulation of every sound because Mandarin is syllable-timed, and the equal stress given to each syllable because Mandarin is not stress-timed, etc.
Therefore, the two major problems for elderly Chinese immigrants are: the linguistic differences between Mandarin and English, and declining cognitive ability, especially in working memory. I have observed these challenges firsthand in my work with CLP participants: it takes many repetitions and specific tips on muscle engagement or placement before their pronunciation sounds native-like, and even if they can correct their pronunciation during the weekly in person sessions, they are unable to remember the right pronunciation in their daily lives.
A practical method that I have seen the learners use is representing the sounds of the English word using Mandarin characters that have similar sounds. There have been handbooks published using this method as well13. Although this is not the most ideal way to learn English, especially if one is aiming to get rid of an accent completely, it is practical and effective for elderly learners who just need to get to a point where they can be understood. This practice is commonly used by the 30+ learners at CLP because it uses familiar phonetic sounds to represent new words, which helps them remember the pronunciations more easily. For the elderly, who are experiencing an age-related memory decline, the familiarity helps them retain the sounds better.
However, there are three limitations to this method:
#1 Learners rely heavily on instructors to teach them the correct pronunciation of each word before being able to create an accurate representation of it in Mandarin; thus, they can only learn a few words a week during class. Although effective for remembering pronunciation, especially for elderly learners, this method is ad hoc and lacks systematic conversion.
#2 Mandarin characters are equally stressed and each syllable is pronounced, leading to inaccurate representations that do not emphasize the stressed syllables in the English word and occasionally add additional syllables14,15. However, stress patterns are critical in English, and their unimportance in Mandarin leads to monotone pronunciation that can be unintelligible11.
#3 The absence of direct counterparts to English phonemes in Mandarin causes substitutions that can result in confusion11,16. For example, many will substitute the Mandarin phoneme /l/ for the English phoneme /r/.
Methodology Overview
This research focuses on the following three problems to address the three limitations mentioned above:
#1 How to systematically represent English words using Mandarin characters with similar sounds.
#2 How to emphasize stressed syllables and de-emphasize other syllables using visual cues.
#3 How to indicate the correct phonemes when a similar phoneme is used because there is no corresponding Mandarin character with the correct sound.
Large Language Models and a Solution for Problem #1:
With the rapid progress of large language models (LLMs)17, there is potential to develop an AI solution for question
#1. Large language models (LLMs), such as ChatGPT, Gemini, and Llama, have emerged as powerful tools for natural language processing tasks, capable of generating contextually rich and linguistically complex outputs. This study uses prompt engineering and three LLMs to generate Mandarin representations for 100 common English words. The performance of this solution has been evaluated.Visual Cue Solution for Problem #2 and #3
LLM generated Mandarin representation shows effectiveness in English pronunciation for elderly Chinese learners. To improve the performance, a set of visual cues are carefully designed in this research to address specific challenges faced by Mandarin-speaking learners of English. Font size variation is used to indicate syllabic stress and IPA-based annotations are used to correct phoneme substitutions. An experiment has been conducted to evaluate the effectiveness of this method.
Methods
Two research experiments were conducted to evaluate the effectiveness of LLM conversion and visual cue solutions respectively.
Experiment 1: LLM for Conversion
Model Selection: Three advanced LLMs were evaluated for their ability to produce Mandarin phonetic approximations of English words: OpenAI’s ChatGPT-4o, Google’s Gemini 1.5, and Meta’s Llama 3.
Data Collection: A validation dataset consisting of 100 frequently used multisyllabic English words was compiled from https://frequencylist.com/. These words were chosen to reflect a broad range of phonetic structures and difficulty levels for Mandarin-speaking English learners. Specifically, the words were selected to represent a wide range of phonetic challenges commonly faced by Mandarin-speaking English learners. These include consonant clusters and substitutions involving /r/–/l/, /s/–/x/–/θ/, and /v/–/f/–/w/. More groups may be added in the future. While many of the words (e.g., doctor, problem, paper) also appear frequently in daily communication, the primary goal was to ensure coverage of these speech categories. This design choice increases the generalizability of the dataset, while still making it applicable to real-life communication.
Prompt Engineering: The prompts given to the LLM have a significant impact on the output18,19,20. Each LLM was given a tailored prompt with examples of English words and their Mandarin phonetic approximations. The prompt instructed the models to output side-by-side tables of English words and their character-based phonetic representations in Mandarin, omitting common loanwords. This is a snapshot of ChatGPT with prompts used for this experiment.. The prompts given were:
#1 The word “beautiful” can be phonetically approximated using Mandarin Chinese characters as “比优提福” (bǐ yōu tí fú). The Mandarin representation of the word “adventure” is “阿德文丘儿” (Ā dé wén qiū ér). Using these examples, make Mandarin Chinese representations of 10 popular English words based on the phonetics. Format using a summary table with first column containing the English word and the second column containing the Mandarin approximations. Also, please ignore common loanwords.
# 2 Please do the same for the following list of words: [list of 100 frequently used words pasted]
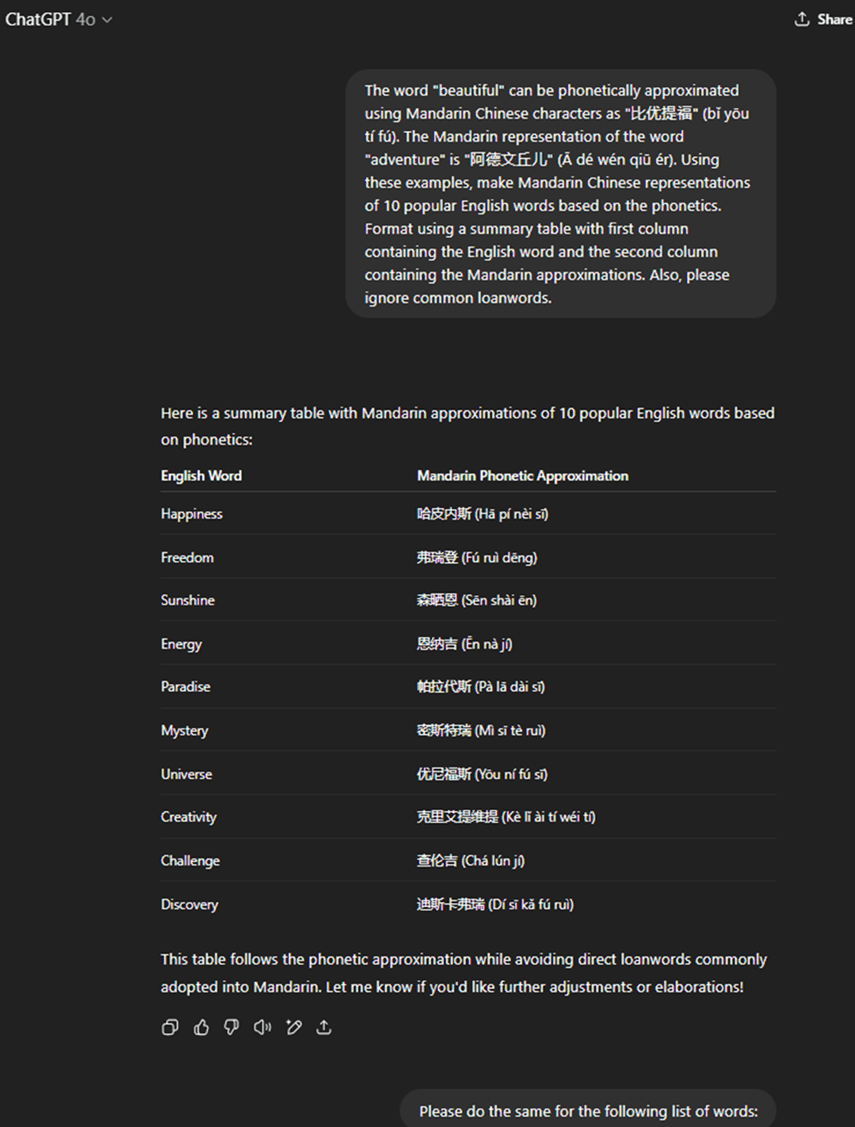
Each model generated responses to the same prompts and word list. The output data were collected.
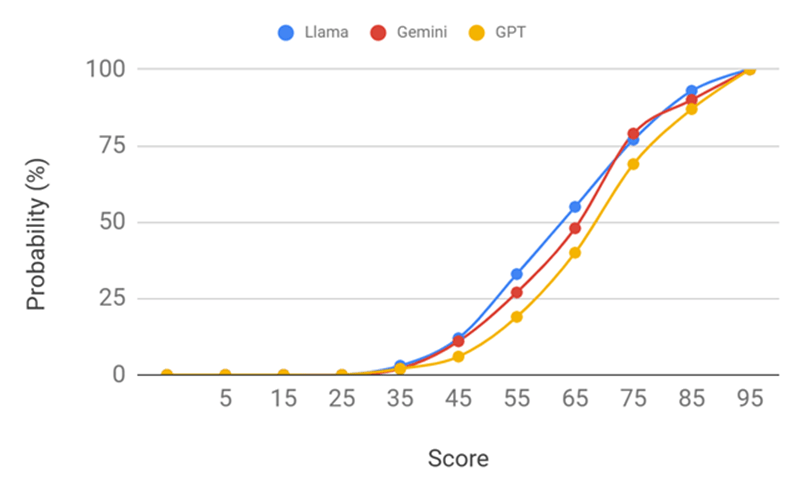
Pronunciation Evaluation: Two native Mandarin speakers (one male and one female, age 50+) participated in pilot testing. Each participant read out each generated Mandarin representation five times into Microsoft Azure’s Pronunciation Assessment tool, which evaluated evaluates an “Accuracy Score” that “indicate[d]s how closely the phonemes match a native speaker’s pronunciation” from 0 to 100. The score focuses on segmental accuracy (phoneme-level matching) rather than prosodic features such as intonation, rhythm, or stress, but the tool provides a “Prosody Score” that could be explored in future work to assess sentence-level fluency. Scores across the five repetitions were consistent (within ±5 points). Figures 1-3 illustrate the score distributions for each model, respectively. Figure 4 presents the cumulative distributions of the three models. The scores were averaged for each model and results were promising: the overall average score was 70.23 across the models. Among the three LLMs, ChatGPT-4o performed the best, with an average score of 73.02. Table 1 shows that it scored highest for three of the four groups we analyzed, but is weaker with /v/–/f/–/w/ substitutions. All models struggled with stress timing, since all Mandarin characters are equally stressed, with adding extra syllables for consonant clusters, and with substituting phonemes for ones that don’t exist in Mandarin.
| ChatGPT-4o | Gemini 1.5 | LLaMA 3 | |
| Consonant Clusters | 64.59 | 59.40 | 61.71 |
| /r/–/l/ | 69.73 | 63.71 | 64.92 |
| /s/–/x/–/θ/ | 66.57 | 65.43 | 57.43 |
| /v/–/f/–/w/ | 62.00 | 63.68 | 60.09 |

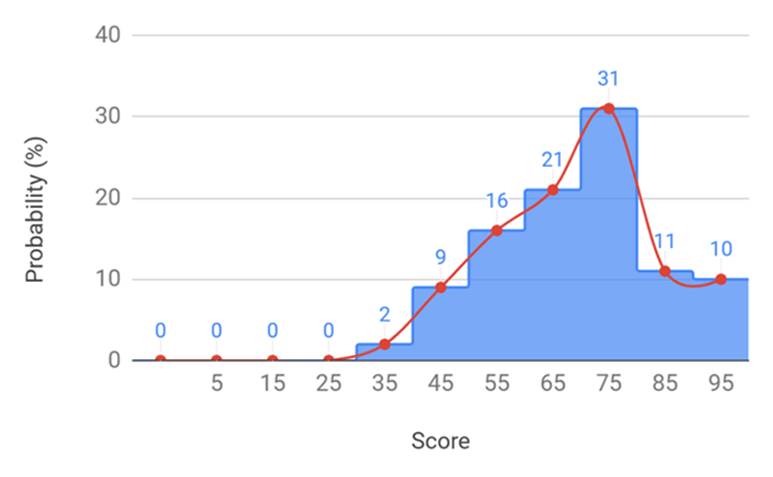

Result Review: I compiled the output data from three models and manually reviewed the 100 words. Table 1 shows selected results and review notes.
| English | ChatGPT-4o | Gemini 1.5 | Llama 3 | Review Notes | Average Accuracy Score |
| Before | 比弗尔 (bǐ fú ěr) | 比佛尔 (bǐ fū ěr) | 比福 (bǐ fú) | Good, but no clear stress on “fore” because Mandarin characters are equally stressed | 86.17 |
| Medicine | 梅迪森 (méi dí sēn) | 梅迪森 (mèi dǐ sēn) | 美地森 (měi dì sēn) | Good, but no clear stress on “me” because Mandarin characters are equally stressed | 74 |
| Interrupt | 英特拉普特 (Yīng tè lā pǔ tè) | 因特拉普特 (yīn tè lǎ pǔ tè) | 因特鲁普特 (yīn tè lǔ pǔ tè) | /l/ substitution for /r/, no clear stress on “rupt” because Mandarin characters are equally stressed, additional syllables | 67.33 |
| Ready | 瑞迪 (ruì dí) | 雷迪 (léi dí) | 雷迪 (léi dí) | /l/ substitution for /r/, no clear stress on “rea” because Mandarin characters are equally stressed | 72.83 |
| Environment | 恩维洛门特 (ēn wéi luò mén tè) | 茵维朗门特 (yīn wēi lǎng mèn tè) | 恩维朗门特 (ēn wéi lǎng mén tè) | /w/ substitution for /v/, no clear stress on “vi” because Mandarin characters are equally stressed, additional syllables | 55 |
| Authority | 奥瑟瑞提 (ào sè ruì tí) | 奥索瑞提 (ào sù ruì tí) | 奥索里提 (ào suǒ lǐ tí) | /s/ substitution for /θ/, no clear stress on “tho” because Mandarin characters are equally stressed | 62.5 |
Experiment 1 demonstrates that LLMs can be used as an effective tool to convert English words into Mandarin phonetic representations. This solution directly addresses problem #1. The LLMs systematically generate Mandarin representations that closely mimic the target English sounds, making it easier for learners to map unfamiliar phonemes to their existing phonetic inventory. This approach offers scalable, automated support for a wide range of vocabulary. The potential impact is promising: by providing linguistically accessible pronunciation tools, it may help learners reduce confusion and build confidence when encountering unfamiliar English words. impact is significant: learners gain immediate linguistically-accessible tools for pronunciation, helping to reduce confusion and build confidence when confronting new English words.
The pronunciation accuracy shown in Experiment 1 is good , but it also indicates that there are still improvements to be made. Namely: stressed syllables disappear due to each character being equally stressed in Mandarin, additional syllables are added due to the lack of consonant clusters in Mandarin and the general rule that characters cannot end in consonants, and substitutions are made for English phonemes that don’t have a corresponding Mandarin character. These challenges align with the fundamental linguistic differences between English and Mandarin mentioned previously in problems #2 and #3. Experiment 2 addresses these issues.
Experiment 2: Visual Cue Solution
Visual Cue Development: Following a manual review of the model outputs by the author, two visual cues were introduced to address common issues such as the lack of stress pattern indication, excess syllables due to Mandarin phonotactics, and phoneme substitutions.
- Stress patterns were represented using varied font sizes (28pt for stressed, 20pt for neutral, 14pt for de-emphasized)
- Substituted phonemes were highlighted and labeled using IPA notation.
Table 2 shows examples with visual cues.
| English | Mandarin Representation with Visual Cues |
| Accidentally | 艾克斯顿特利 |
| Guarantee | 盖(r)伦提 |
| Wealthy | 威尔(l) (th)西 |
| Every | 埃(v)夫瑞 |
ChatGPT-4o is used to produce Mandarin phonetic approximations with these visual cues to the same 100 frequently used multisyllabic English words in Experiment 1.
Prompt Engineering Process: The following prompts were used.
#1 The CSV attached contains Mandarin approximations of English words based on phonetics. For example, the word “beautiful” can be phonetically approximated using Mandarin Chinese characters as “比优提福” (bǐ yōu tí fú). However, there exist sounds in English that cannot be easily represented using Mandarin characters. The absence of direct counterparts to English phonemes in Mandarin causes substitutions that can cause confusion. For example, many will substitute the Mandarin phoneme /l/ for the English phoneme /r/. Please add a labeled IPA notation in those cases. For example, “guarantee” should be converted to “盖(r)伦提” by adding “(r)” in front of “伦”, and bolding “盖” for stressing. Please do this for all 100 words.
#2 Here are some more examples to learn from:
Accidentally 艾克斯顿特利 (Ài kè sī dùn tè lì)
Guarantee 盖(r)伦提 (Gài lún tí)
Volunteer (v)沃伦提尔 (Wò lún tí ěr)
Television 特勒(v)维申 (Tè lè wéi shēn)
Every 埃(v)夫瑞 (Āi fū ruì)
Author 奥(th)瑟 (Ào sè)
Radio (r)雷迪欧 (Léi dí ōu)
#3 Don’t make redundant annotations: they should only be there when a different phoneme is substituted. Ex. Problem should not be 普(l)拉布莱姆, but 普(r)拉布莱姆 since the /l/ phoneme is substituted but it should be /r/, and Other should not be 阿(z)泽, but 阿(θ)泽. Correct all annotations.
#4 Don’t add /l/ if the mandarin character starts with l (ex. 拉). Annotations are for when the mandarin character phonemes don’t match with the voiced English ones: ex. it says 拉 but it should be “ra,” so you write (r)拉.
#5 To make the pronunciation better, I want to use different font sizes 14, 20, 28 for each Mandarin character to represent the emphasis of certain parts of the word. For example, “Beautiful” is represented as “比优提福” and the font size 优 should be bigger than other characters to show the emphasis since it is pronounced b-EAU-ti-ful. Use the pronunciation of the word in English to find the stressed parts and make the font size larger for the corresponding characters in its Mandarin phonetic representation. Stresses are always on the vowel of the stressed syllable. Also, make characters that should be deemphasized smaller in font (ex. for accidentally, the 克 in 艾克斯顿特利 should be smaller because it is deemphasized as you don´t voice the e vowel in 克, as it should connect to the 斯). This is because Mandarin characters don’t have consonant clusters, so excess vowels are added and thus need to be deemphasized.
Note: The CMU Pronouncing Dictionary was provided to the model. (https://github.com/Alexir/CMUdict.git, file cmudict-07.b)
Explanation Guide: An guide was created to explain the visual cue system, with a legend and an example.
Legend
| Cue | Meaning (English) | 中文解释 |
| 28pt 大 | Stressed syllable | 重音 |
| 20pt 中 | Normal syllable | 正常读音 |
| 14pt 小 | De-emphasized syllable (particularly the vowel) | 弱读音(不强调,尤其是元音) |
| () | When you see a label in parentheses, replace the consonant in the adjacent Mandarin character with the one shown in parentheses. | 当你看到括号里的标记时,把旁边汉字的辅音换成括号里的发音。 |
| (r) | Pronounce like English r | 按英文 r 发音 |
| (l) | Pronounce like English l | 按英文 l 发音 |
| (th) | Pronounce like English th (e.g., think) | 按英文 th 发音 |
| (v) | Pronounce like English v (e.g., voice) | 按英文 v 发音 |
Example:
| Wealthy | 威尔(l) (th)西 |
| Character & Cue | English Explanation | 中文解释 |
| 威 | Main stress on “Wea–.” | 表示 “Wea–”,重音在这里。 |
| 尔(l) | Not pronounced as “ěr.” Replace the consonant with English L, and connect the vowel to the previous syllable because it is de-emphasized. | 不按 “ěr” 发音,而是把辅音换成 英文 L,并且要轻读,把元音连接到前一个音节。 |
| (th)西 | Use the English th sound here instead of Mandarin “x,” pronounced at a normal weight. | 这里用 英文 th 的发音,而不是汉字的 “x”,正常读音。 |
| Together, these yield a close approximation of Wealthy. | 最终整体发音接近英文 Wealthy。 |
Evaluation Rubric: An evaluation rubric was created for evaluating the accuracy of the generated Mandarin representations, which will be used in the future to enhance the model.
| 5 | 4 | 3 | 2 | 1 | |
| Correct Mapping of Phonemes | All English phonemes mapped to the closest Mandarin equivalents | One or two minor deviations that don’t affect intelligibility | Several mismatches but overall resemblance maintained | Frequent mismatches, many sounds obscured | Very misleading, pronunciation diverges significantly |
| Correct Stress Placement | Primary (and secondary, if applicable) stress marked correctly | Primary stress correct but secondary stress missing or inconsistent | Stress placed on part of the correct syllable but not the main character | Completely misplaced stresses | No stress indicated at all |
| Correct De-emphasis of Characters | All unstressed/inserted syllables consistently de-emphasized | Most unstressed/inserted syllables de-emphasized correctly | Some correct, but others wrongly de-emphasized | Frequent mis-marking; important syllables wrongly de-emphasized | No attempt at de-emphasis |
| Substitution Annotations | All substituted phonemes (/r/, /th/, /v/, etc.) clearly and consistently labeled | Most substitutions labeled; a few missing | Several important substitutions unlabeled | No necessary substitutions labeled | Incorrect substitution labeling |
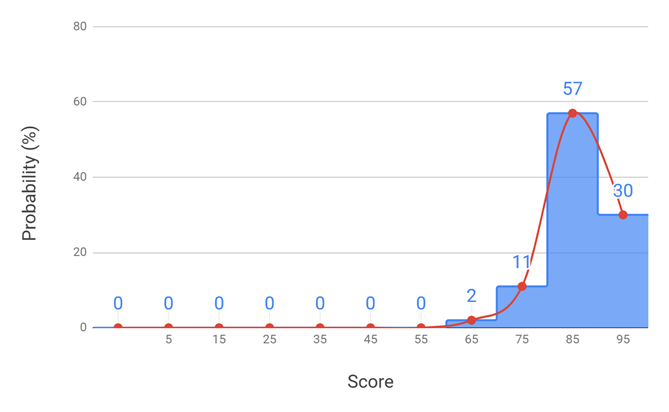
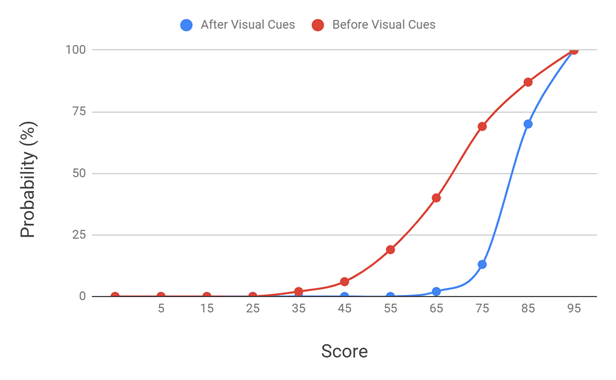
Pronunciation Evaluation: A second pronunciation test (again using the Pronunciation Assessment tool in Microsoft Azure AI Speech Services) was conducted with four native Mandarin speakers (male and female, age 50+, of varying English ability) on the 100-word test set after visual cues were added. Scores across the five repetitions were generally stable (within ±5 points), with a slight tendency for the first attempt to be lower when participants occasionally misread the cues. Figure 5 illustrates the score distribution for the visual cue enhanced Mandarin representations. Figure 6 presents the cumulative score distribution comparison before and after the addition of visual cues.
When visual cues were introduced, the overall average score increased by 11% from 69.61 to 80.20. Participants were able to emphasize stressed syllables and those with slightly more experience with English were able to use the phonetic labels to correct. Participants still struggled with not adding additional syllables to consonant clusters, as not all de-emphasized characters were written in 14pt font. This demonstrates thatThe visual augmentation cue system meaningfully enhances learners’ ability to approximate native English pronunciation. The improvement was consistent across both all test participants.
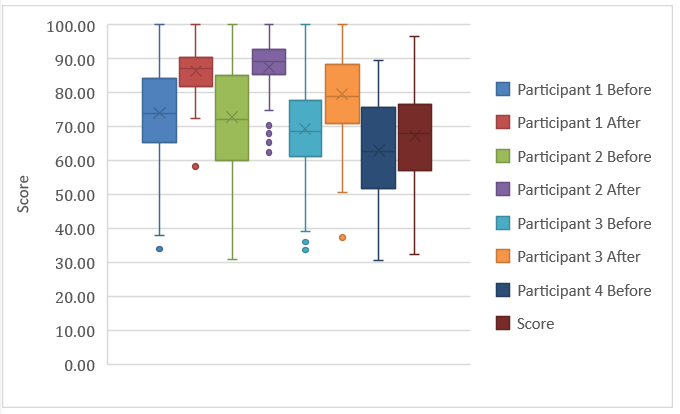
| Before Visual Cues | After Visual Cues | Average Improvement | |||
| Average | Standard Deviation | Average | Standard Deviation | ||
| Participant 1 | 73.98 | 14.83 | 86.4 | 7.38 | 12.42 |
| Participant 2 | 72.77 | 15.88 | 87.62 | 8.01 | 14.85 |
| Participant 3 | 69.34 | 14.47 | 79.77 | 12.05 | 10.43 |
| Participant 4 | 63.01 | 13.41 | 67.19 | 13.29 | 4.18 |
User Feedback
User Survey: A survey was conducted with the study’s participants to test their understanding of the visual cue system, assess whether the explanation guide was clear, get feedback on ease of use and helpful cues, compare the method with other approaches, and identify desired features for a future mobile application. Results showed that all participants correctly interpreted the different font sizes and parenthetical cues. Half found the guide “very clear” and half “mostly clear.” Most participants found the font-size cues easy to read, while substitution labels were seen as only “somewhat easy” to read. Compared to pinyin or mimicking natives, most found the system “much more helpful,” and all reported greater confidence in their pronunciation when using the system. The most useful cue was font size, followed by explanation of examples and substitution labels. All respondents reported that using the system helps them remember pronunciations for longer, with half reporting “much longer,” but more testing will need to be conducted to confirm. For future development of a mobile application, the participants all indicated that audio playback of each word, practice exercises, regular review reminders, and a scoring system would be helpful features, with some indicating interest in customizable font sizes, more examples with explanations, and a bilingual search function.
Discussion
This study demonstrates that large language models (LLMs) can successfully generate Mandarin character representations that approximate the phonetics of English words systematically with designed prompts. Using Microsoft Azure AI Speech Services, we validated that the generated outputs achieved a solid baseline accuracy (~70), with ChatGPT-4o performing best. In preliminary tests, the introduction of visual cues to indicate stress patterns and phoneme substitutions led to a 11% improvement in pronunciation accuracy.
The results underscore the potential of leveraging generative AI to address language learning challenges among elderly immigrants. The systematic phonetic representation provides a bridge between unfamiliar English sounds and familiar Mandarin characters. This not only enhances pronunciation retention but also empowers a traditionally underserved demographic—elderly Chinese immigrants—with accessible tools. Additionally, visual cues added to the Mandarin representations can enhance pronunciation accuracy.
All three core objectives of the study were effectively addressed:
#1 Systematic representation of English using Mandarin characters was achieved using LLMs.
#2 Visual cues for stress and syllable emphasis were designed and validated.
#3 Substituted phonemes were successfully highlighted and labeled for correction, improving clarity.
Together, these components form an integrated, AI-powered solution that enhances pronunciation learning in a structured, scalable manner for elderly Chinese immigrants.
Limitations
This study is limited by a relatively small dataset (100 words) and a small participant pool (two four speakers). Additionally, Mandarin phonetic representations may still carry inherent ambiguity due to the language’s constraints.
Future Work
Future work should expand the dataset to include a wider range of English vocabulary to improve accuracy. This should encompass largely of commonly used words in daily life.
Future work should also focus on increasing the accuracy of the conversion process, especially the visual cue generation process through fine-tuned LLM models to ensure consistency and scalability. Future evaluations should involve a larger and more demographically diverse pool of Mandarin-speaking participants including learners of different ages, regional dialects, and English proficiency levels. A broader testing base will help assess the effectiveness of the AI model and visual cue system across a spectrum of learners. Additionally, testing should be performed at intervals to assess longer-term benefits of the system.
While this study focused on evaluating the new system in isolation, future work will explore controlled comparisons against traditional pronunciation aids such as pinyin, sound-it-out guides, and audio playback tools, to assess whether visual cues lead to better retention or accuracy.
Additionally, future work should explore the development of a mobile application to deploy the AI-based solution practically and accessibly. A mobile application would offer real-time feedback and personalized progress tracking to assist retention. This application would facilitate large scale testing and valuation of this approach. With this application, elderly learners can practice outside of classroom settings. A mobile application would also reach a larger population of elderly Mandarin-speaking learners. User feedback indicated strong interest in an audio playback feature, recording and scoring, and periodic review reminders. We also plan on including opt-in testing to assess long-term gains. Here is an image of what the application would look like:
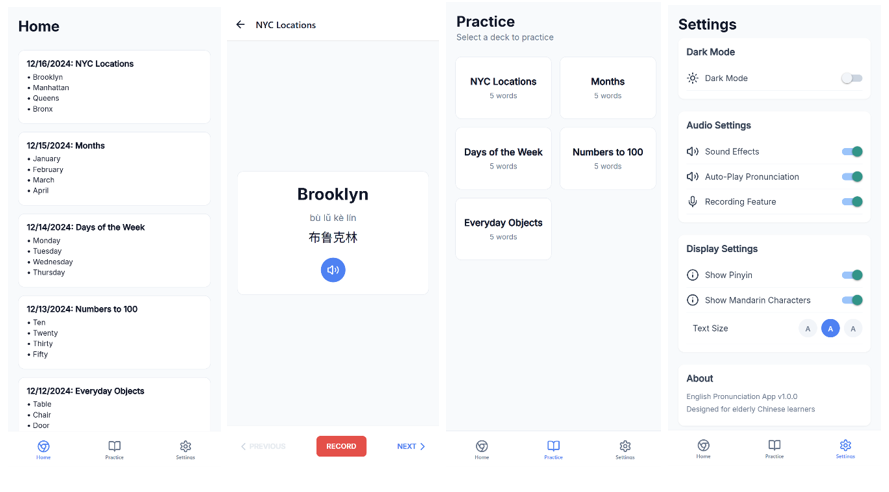
Closing Thoughts
By combining the power of artificial intelligence with an understanding of linguistic barriers elderly immigrants face, this research presents a novel path forward in addressing language learning challenges. With further development, this AI solution can help empower thousands of elderly immigrant learners to find their voice in a new language—and in a new home.
References
- H. Al Shamsi, A. G. Almutairi, S. Al Mashrafi & T. Al Kalbani. Implications of language barriers for healthcare: A systematic review. Oman Medical Journal, 35(2), e122 (2020). [↩]
- M. Pandey, R. G. Maina, J. Amoyaw, Y. Li, R. Kamrul, C. R. Michaels & R. Maroof. Impacts of English language proficiency on healthcare access, use, and outcomes among immigrants: a qualitative study. BMC Health Services Research, 21(1), 741 (2021). [↩]
- H. Jamil, S. S. Kanno, R. Abo-Shasha, M. M. AlSaqa, M. Fakhouri & B. B. Arnetz. Promoters and barriers to work: a comparative study of refugees versus immigrants in the United States. The New Iraqi Journal of Medicine, 8(2), 19–28 (2012). [↩]
- H. Jamil, S. S. Kanno, R. Abo-Shasha, M. M. AlSaqa, M. Fakhouri & B. B. Arnetz. Promoters and barriers to work: a comparative study of refugees versus immigrants in the United States. The New Iraqi Journal of Medicine, 8(2), 19–28 (2012). [↩]
- A. Pot, M. Keijzer & K. De Bot. The language barrier in migrant aging. International Journal of Bilingual Education and Bilingualism, 23(9), 1139–1157 (2018). [↩]
- J. M. Levis. Intelligibility, Oral Communication, and the Teaching of Pronunciation. Cambridge University Press (2018). [↩]
- M. L. Price. The Subjective Experience of Foreign Language Anxiety: Interviews with Highly Anxious Students [Extras]. Prentice-Hall (1991). [↩]
- M. Baran-Łucarz. The link between pronunciation anxiety and willingness to communicate in the foreign-language classroom: The Polish EFL context. Canadian Modern Language Review, 70(4), 445-473 (2014). [↩]
- L. C. Ehri. Grapheme–phoneme knowledge is essential for learning to read words in English. Word Recognition in Beginning Literacy 3-40 (2013). [↩]
- F. Zhang & P. Yin. A study of pronunciation problems of English learners in China. Asian Social Science, 5(6), 141-146 (2009). [↩] [↩]
- F. Zhang & P. Yin. A study of pronunciation problems of English learners in China. Asian Social Science, 5(6), 141-146 (2009). [↩] [↩] [↩]
- A. F. Jati, M. Rovikasari & H. Mutammimah. The obstacles in teaching English for elderly learners: a case study in a sewing group. Educational Tracker: Teaching English as a Foreign Language Journal, 3(1), 1-10 (2024). [↩]
- W. H. Li. 会说中文就会说英文: 零基础学会说英语 [If you can speak Mandarin, you can speak English: Learn to speak English from scratch]. Jiangsu Science and Technology Publisher (2019). [↩]
- F. Zhang & P. Yin. A study of pronunciation problems of English learners in China. Asian Social Science, 5(6), 141-146 (2009). [↩]
- L. Ho. Pronunciation problems of PRC students. Teaching English to Students from China, 138-157 (2003). [↩]
- L. Ho. Pronunciation problems of PRC students. Teaching English to Students from China, 138-157 (2003). [↩]
- N. L. Rane, A. Tawde, S. P. Choudhary & J. Rane. Contribution and performance of ChatGPT and other Large Language Models (LLM) for scientific and research advancements: a double-edged sword. International Research Journal of Modernization in Engineering Technology and Science, 5(10), 875-899 (2023). [↩]
- S. Vatsal & H. Dubey. A survey of prompt engineering methods in large language models for different nlp tasks. arXiv.org arXiv:2407.12994 (2024). [↩]
- P. Sahoo, A. K. Singh, S. Saha, V. Jain, S. Mondal & A. Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv.org arXiv:2402.07927 (2024). [↩]
- B. Chen, Z. Zhang, N. Langrené & S. Zhu. Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review. arXiv.org arXiv:2310.14735 (2023). [↩]



{kind=link}